DragAnything: Motion Control for Anything using Entity Representation
Weijia Wu1,2,3,
Zhuang Li1,
Yuchao Gu3,
Rui Zhao3,
Yefei He2
David Junhao Zhang3,
Mike Zheng Shou3✉
Yan Li1,
Tingting Gao1,
Di Zhang1,
1Kuaishou Technology
2Zhejiang University
3Show Lab, National University of Singapore
-
New insights for trajectory-based controllable generation that reveal the differences between pixel-level motion and entity-level motion.
-
Different from the drag pixel paradigm, we present DragAnything, which can achieve true entity-level motion control with the entity representation.
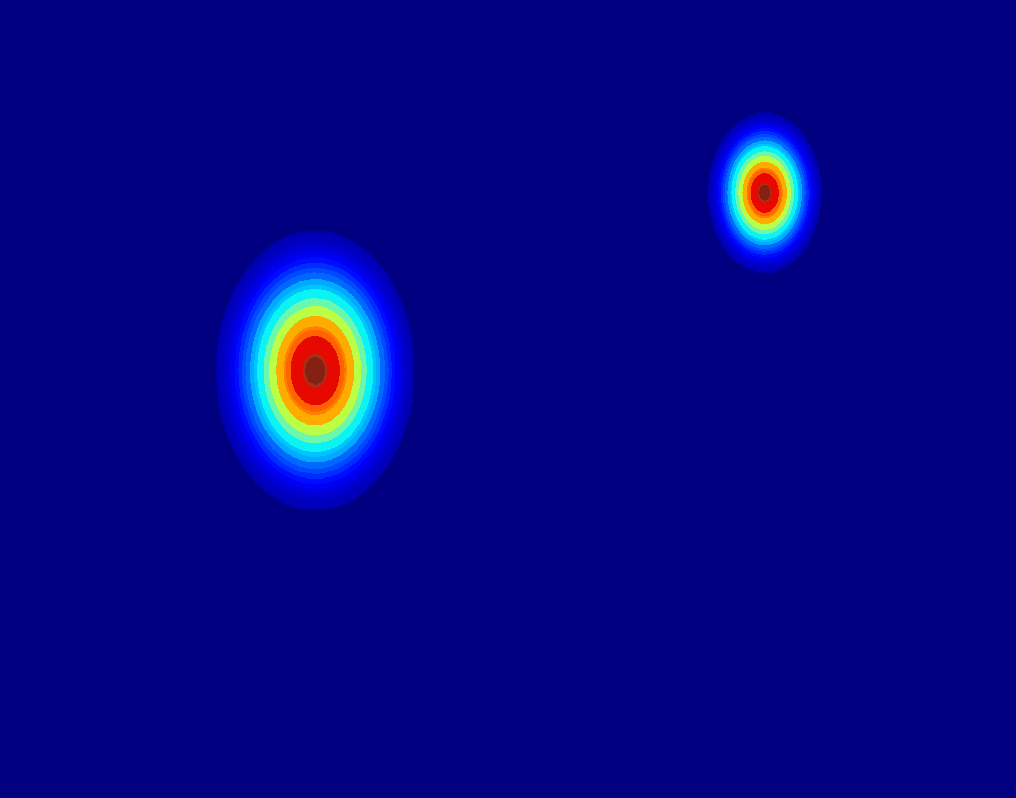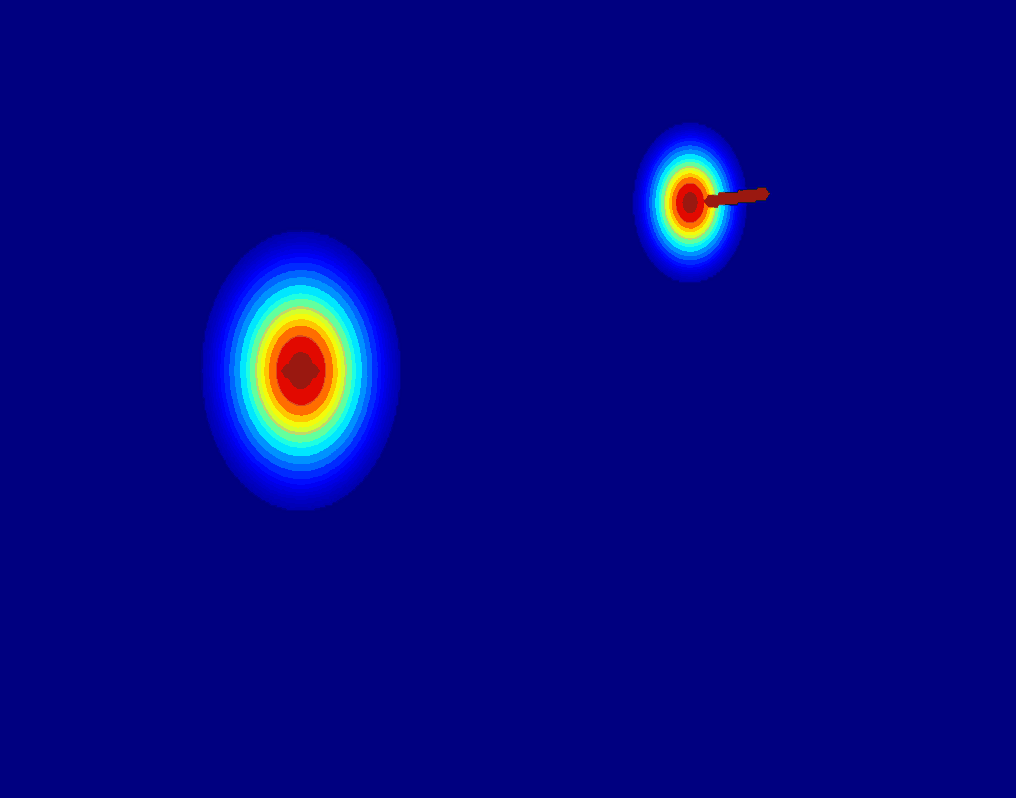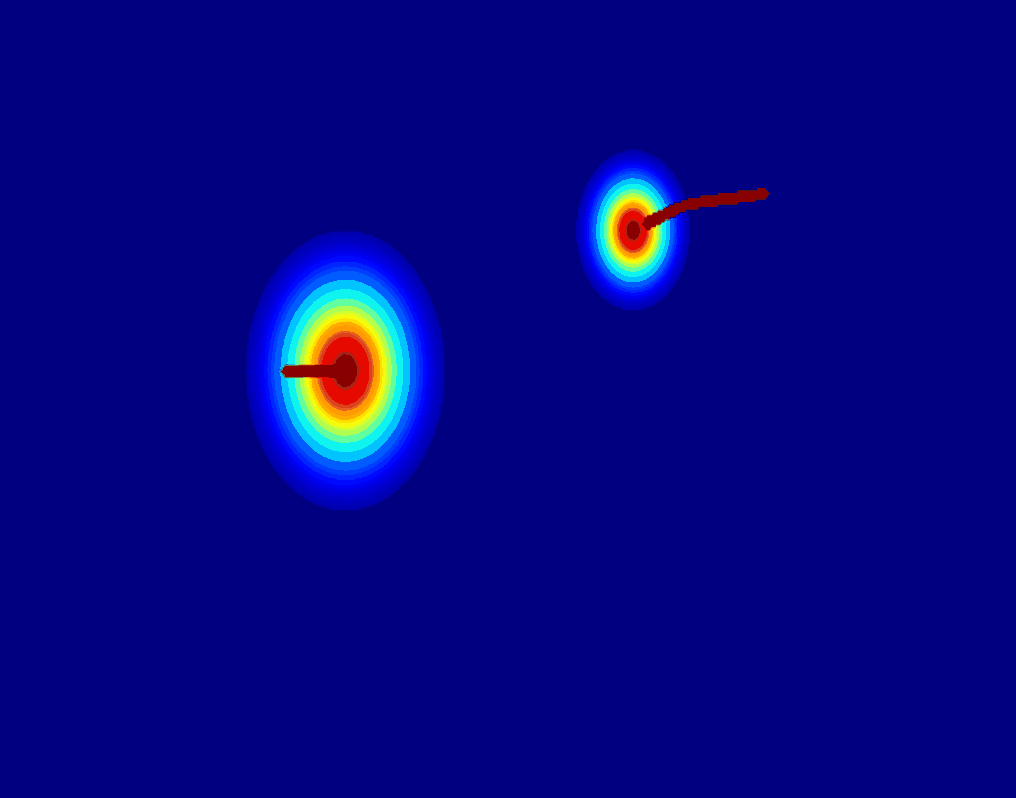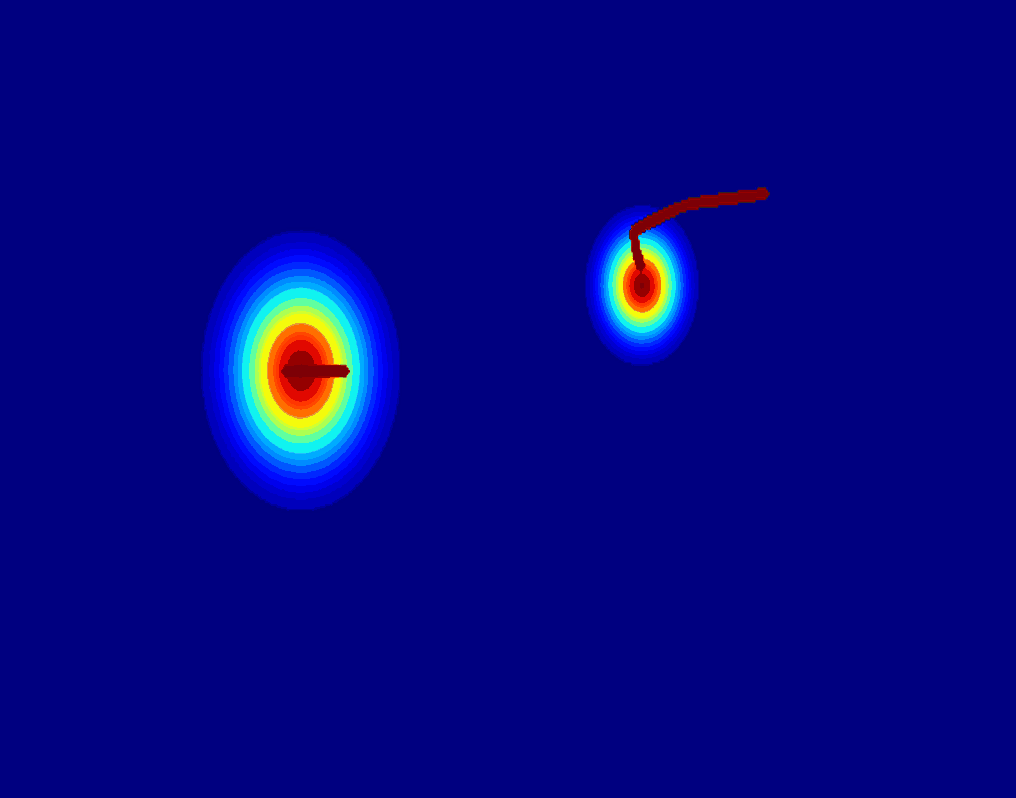
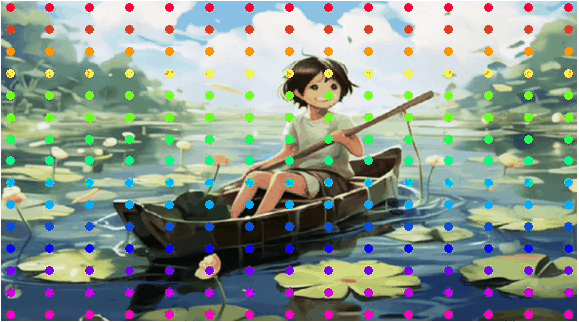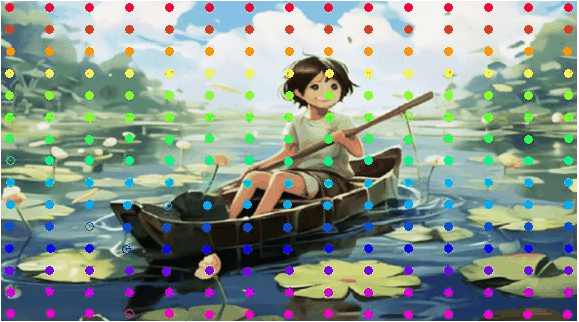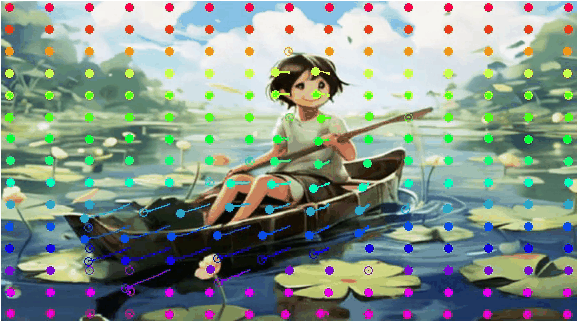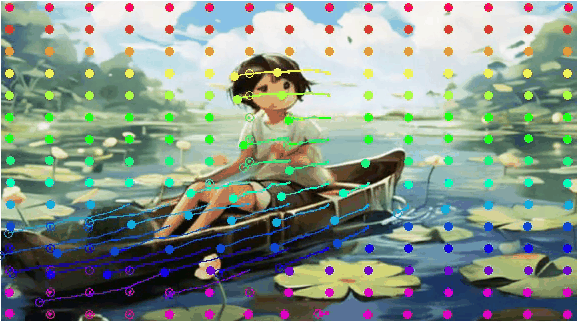
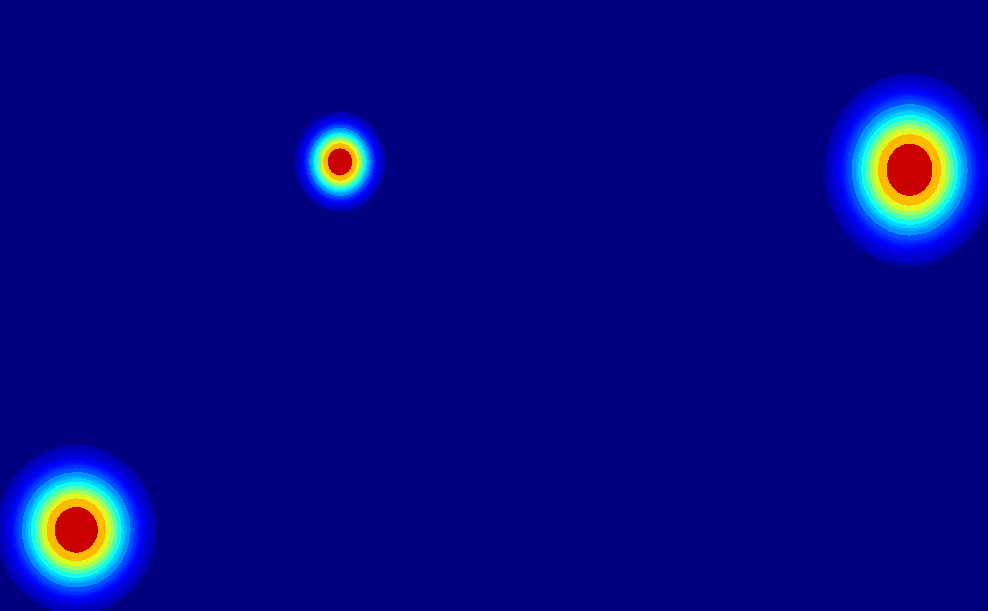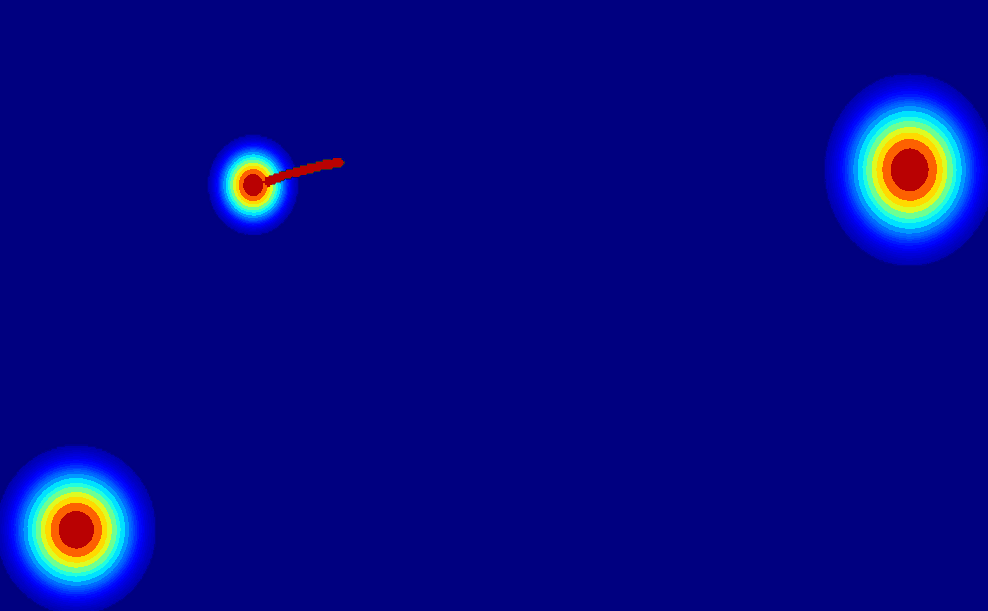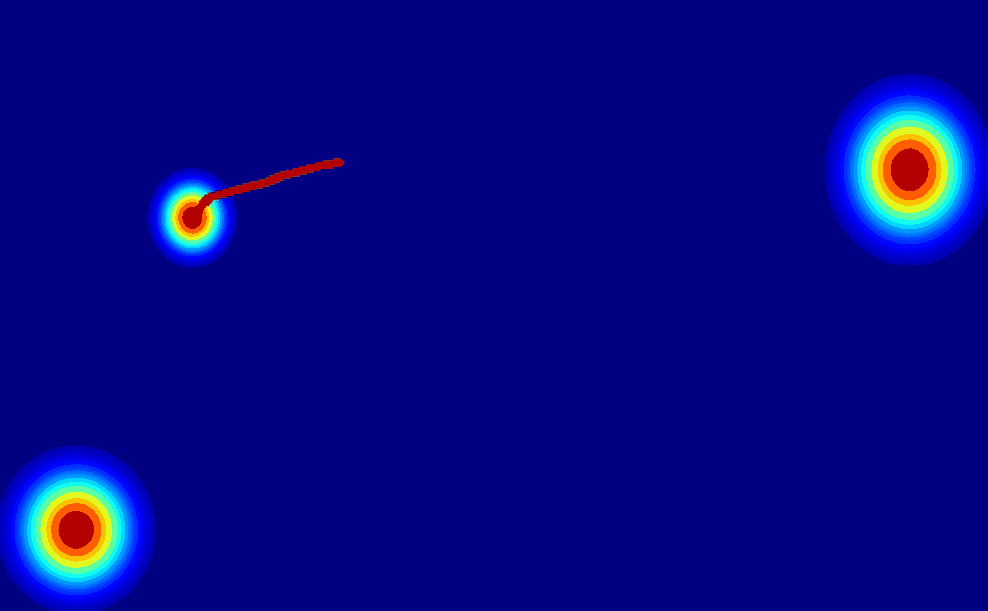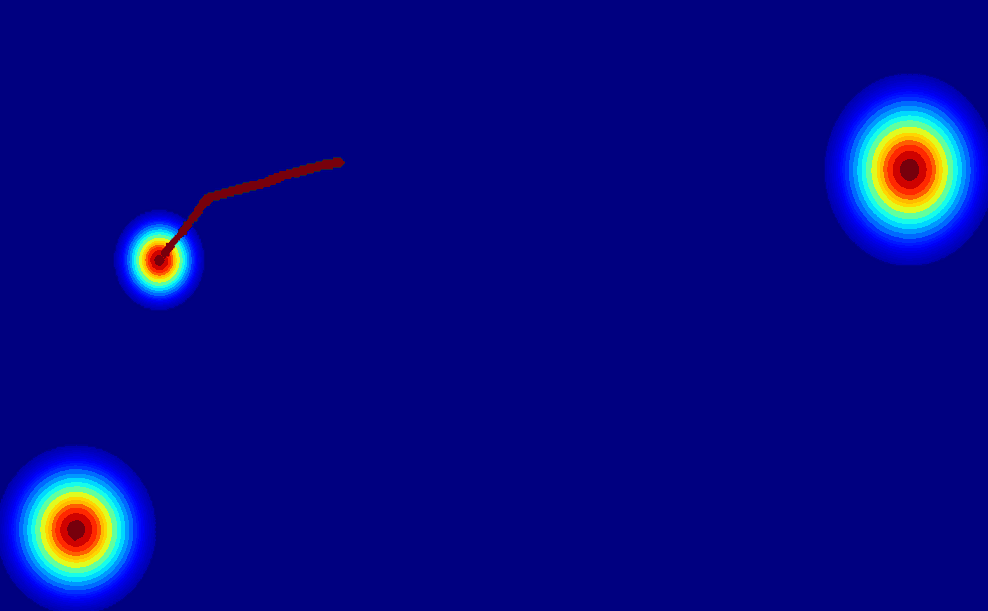
User-Trajectory Interaction with SAM
-
These results are generative with only one unified trained model.
| Input Image |
Drag point with SAM |
2D Gaussian Trajectory |
Generated Video |
 |
 |
.gif) |
.gif) |
|
 |
 |
1.gif) |
|
 |
 |
1.gif) |
|
 |
1.gif) |
 |
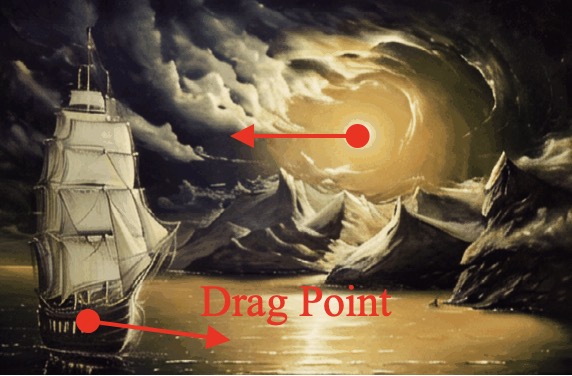
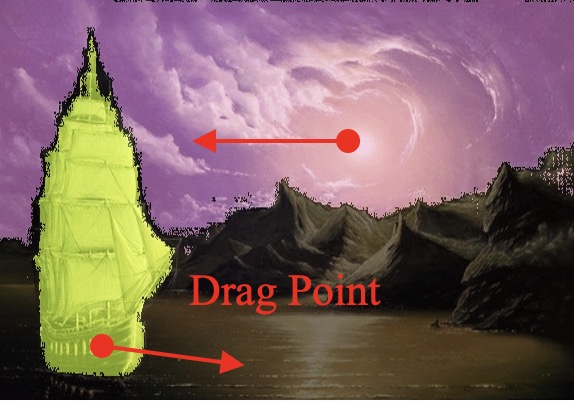
Comparison with DragNUWA
-
DragNUWA leads to distortion of appearance first row, out-of-control sky and ship third row, incorrect camera motion (fifth row), while DragAnthing enables precise control of motion.
| Model |
Input Image and Drag |
Generated Video |
Visualization for Pixel Motion |
| DragNUWA |
 |
 |
 |
| Ours |
 |
 |
 |
| DragNUWA |
 |
 |
 |
| Ours |
 |
 |
 |
| DragNUWA |
 |
 |
 |
| Ours |
 |
 |
 |
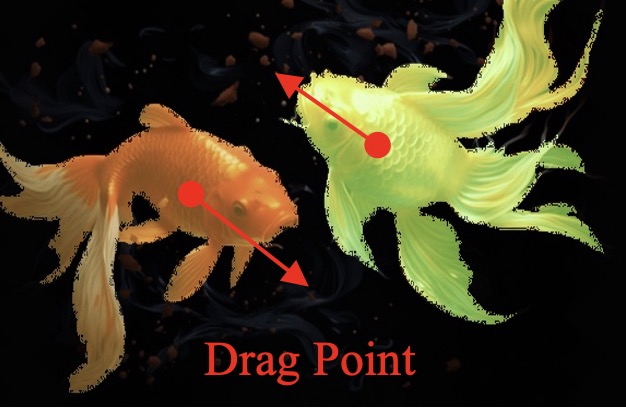
More Visualization for DragAnything
-
The proposed DragAnything can accurately control the motion of objects at the entity level, producing high-quality videos.
The visualization for the pixel motion of 20-th frame is obatined by Co-Track.
| Drag point with SAM |
2D Gaussian |
Generated Video |
Visualization for Pixel Motion |
 |
 |
 |
 |
 |
.gif) |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
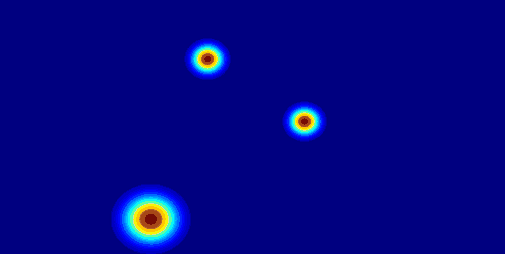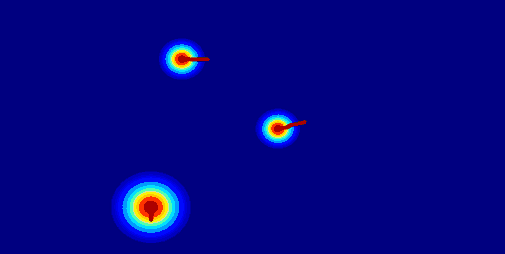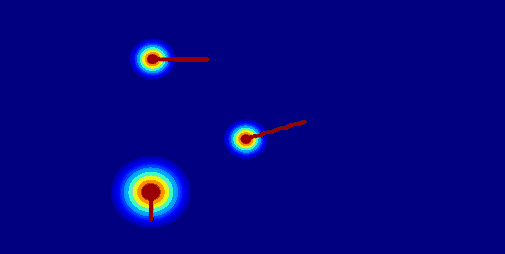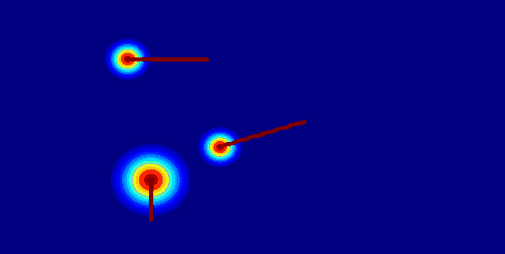 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
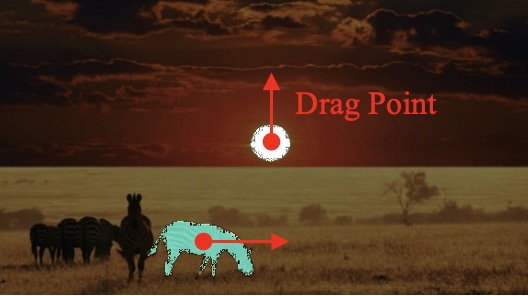
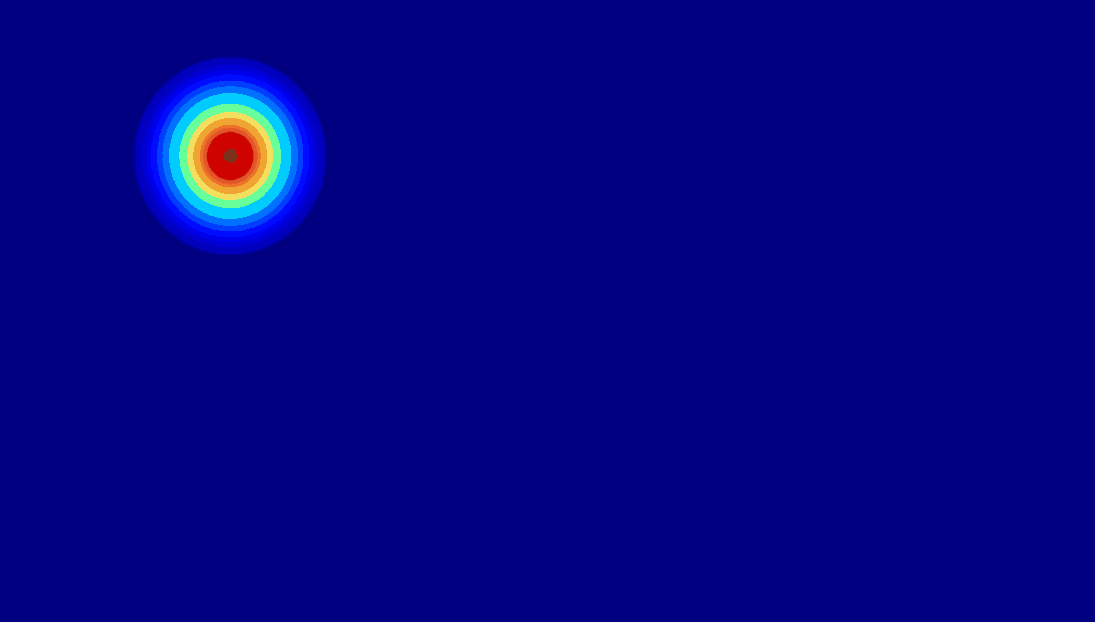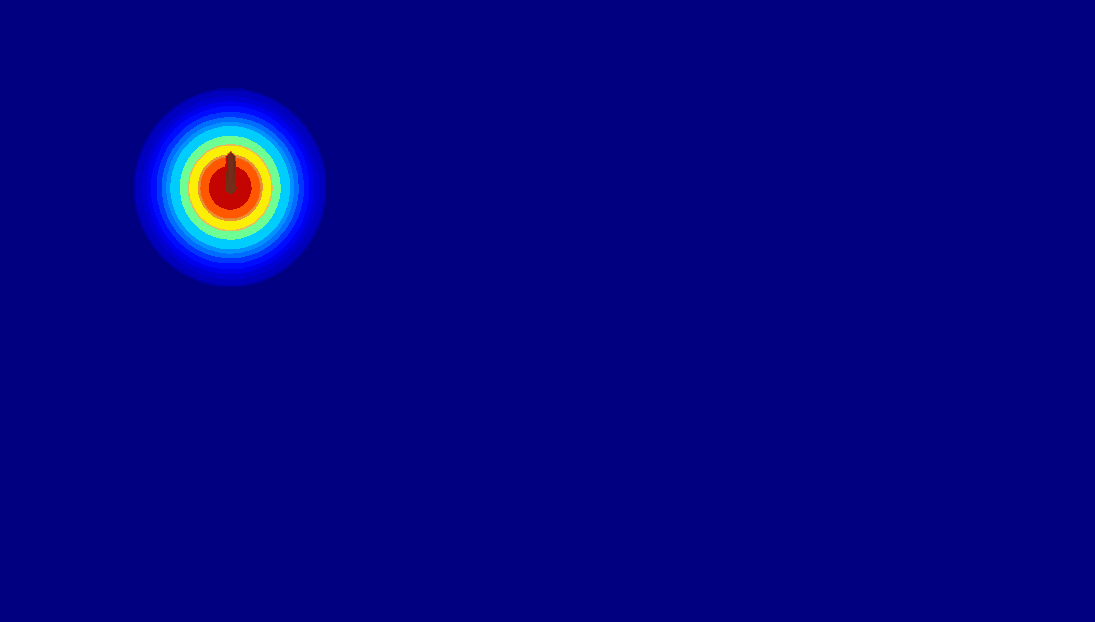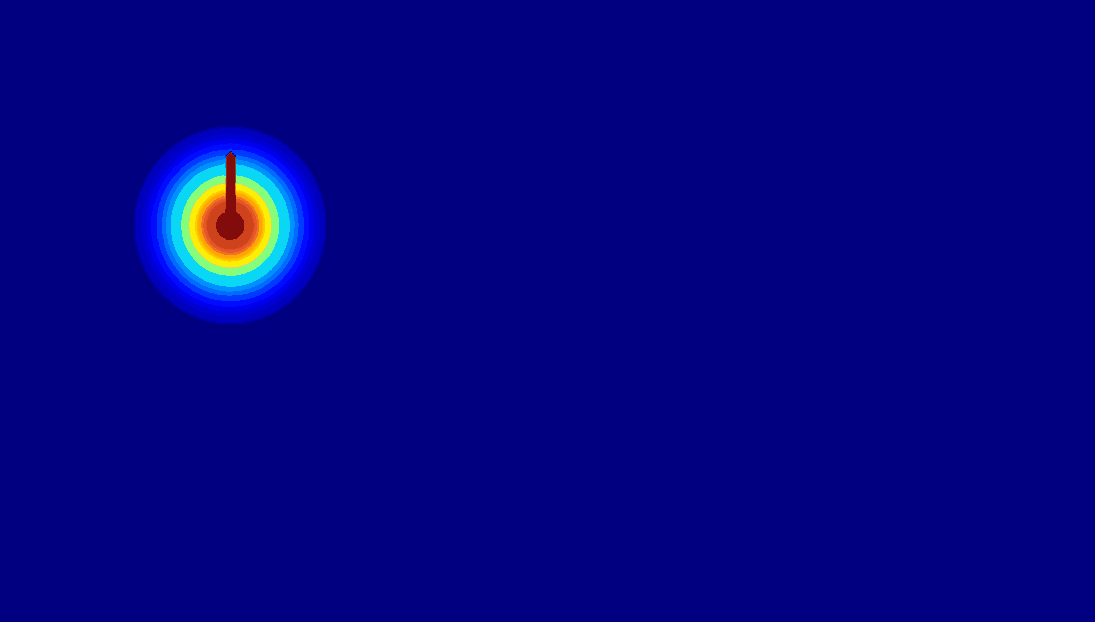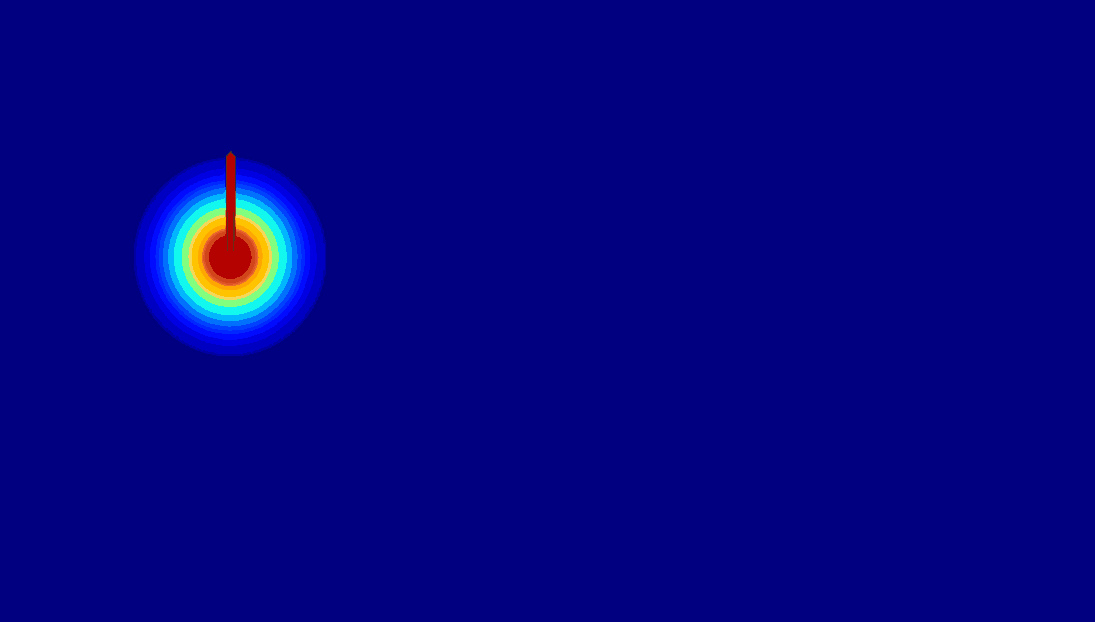
Various Motion Control from Anything
-
The proposed DragAnything can achieve diverse motion control, such as control of foreground, background, and camera.
| Drag point with SAM |
2D Gaussian |
Generated Video |
Visualization for Pixel Motion |
 |
 |
.gif) |
 |
 |
 |
.gif) |
 |
| (a) Motion Control for Foreground |
 |
 |
.gif) |
 |
 |
 |
.gif) |
 |
| (b) Motion Control for Background |
 |
 |
 |
 |
 |
 |
 |
 |
| (c) Simultaneous Motion Control for Foreground and Background
|
 |
 |
.gif) |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| (d) Motion Control for Camera Motion
|
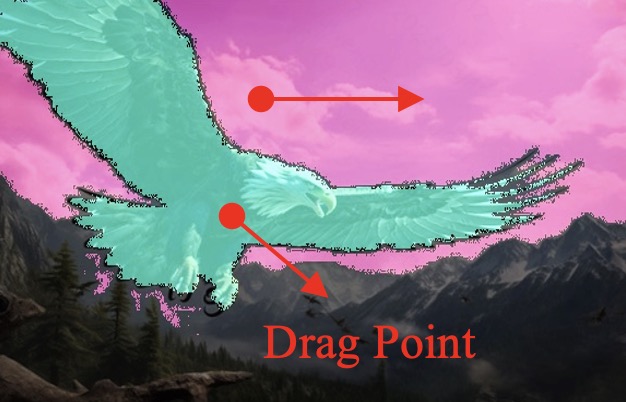
Bad Cases for DragNUWA
-
Current models are constrained by the performance of the foundation model, Stable Video Diffusion, and cannot generate scenes with very large motions. It is obvious that in the first column of video frames, the legs of dinosaur don't adhere to real-world constraints. There are a few frames where there are five legs and some strange motions. A similar situation occurs with the blurring of the wings of eagle in the second row. This could be due to excessive motion, exceeding the generation capabilities of the foundation model, resulting in a collapse in video quality.
| Model |
Input Image and Drag |
Generated Video |
Visualization for Pixel Motion |
 |
 |
 |
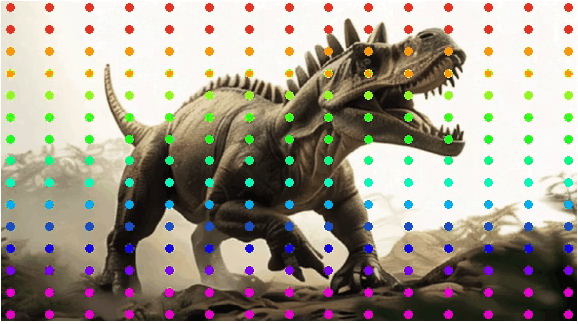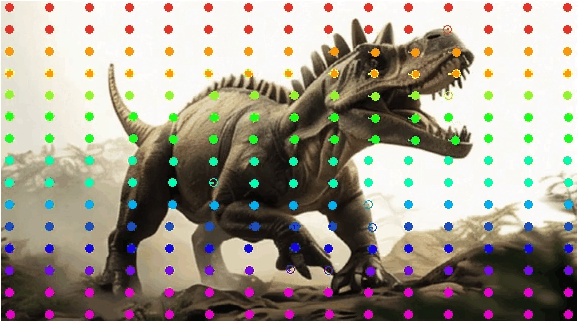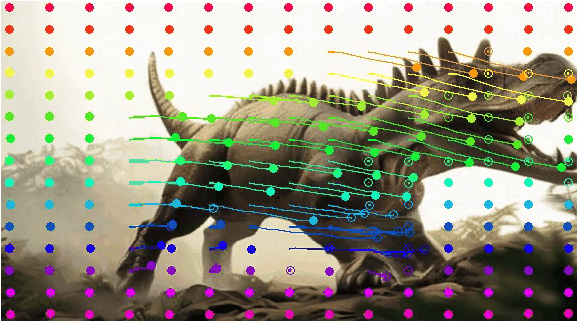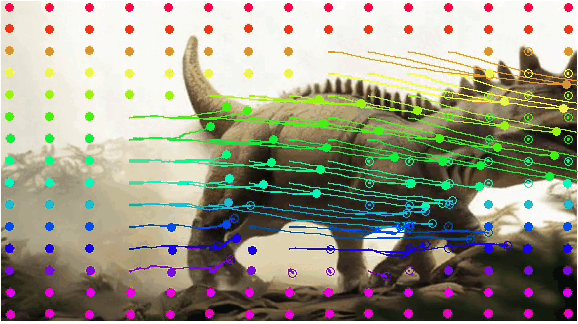 |
 |
|
 |
 |
Abstract
We introduce DragAnything, which utilizes a entity representation to achieve motion control for any object in controllable video generation.
Comparison to existing motion control methods, DragAnything offers several advantages.
Firstly, trajectory-based is more user-friendly for interaction, when acquiring other guidance signals (e.g., masks, depth maps) is labor-intensive.
Users only need to draw a line (trajectory) during interaction.
Secondly, our entity representation serves as an open-domain embedding capable of representing any object, enabling the control of motion for diverse entities, including background.
Lastly, our entity representation allows simultaneous and distinct motion control for multiple objects.
Extensive experiments demonstrate that our \ours achieves state-of-the-art performance for FVD, FID, and User Study, particularly in terms of object motion control, where our method surpasses the previous methods (e.g., DragNUWA) by 26% in human voting.
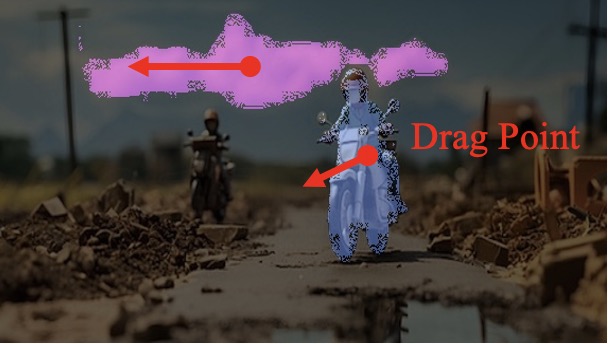
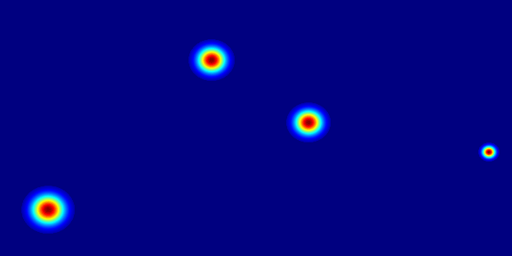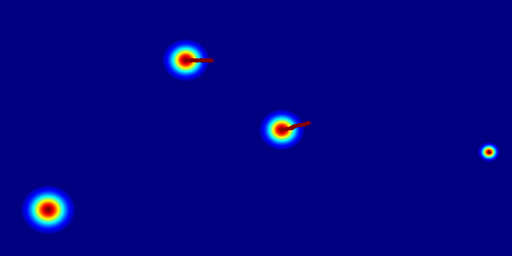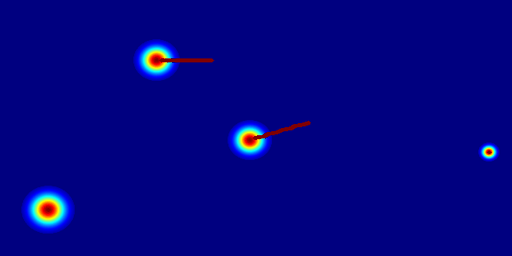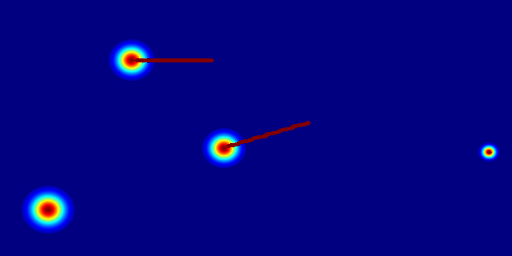
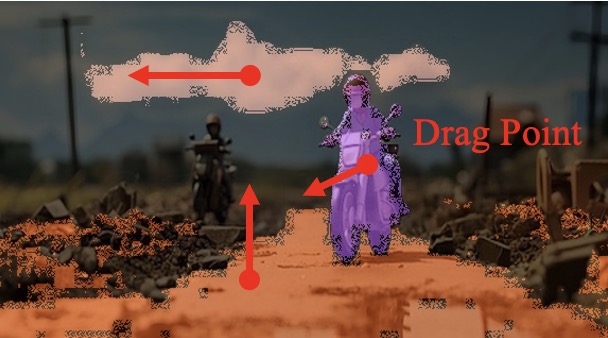
Motivation
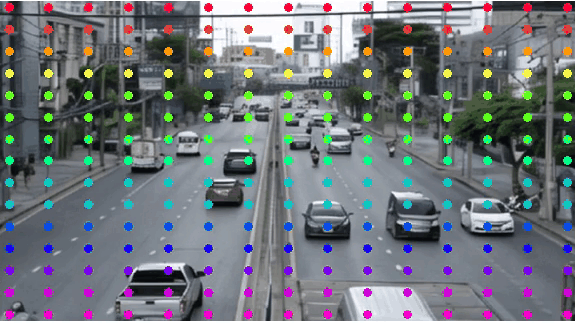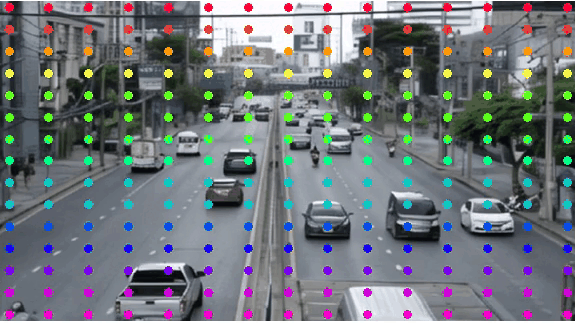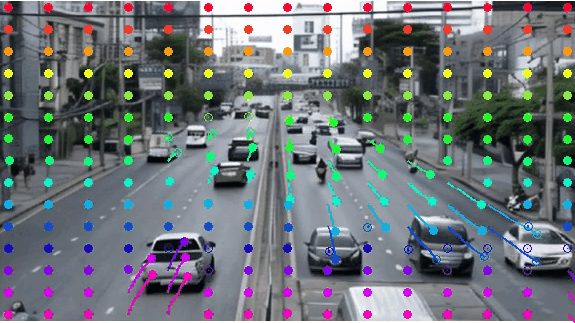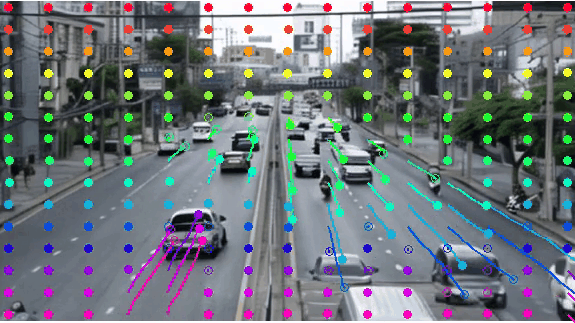
Insight 1: The trajectory points on the object cannot represent the entity. From the pixel motion trajectories of DragUNWA, it is evident that dragging a pixel point of the cloud does not cause the cloud to move; instead, it results in the camera moving up. This indicates that the model cannot perceive our intention to control the cloud, implying that a single point cannot represent the cloud.
Insight 2: For the trajectory point representation paradigm pixels closer to the drag point receive a greater influence, resulting in larger motions. By comparison, we observe that in the videos synthesized by DragNUWA, pixels closer to the drag point exhibit larger motion. However, what we expect is for the object to move as a whole according to the provided trajectory, rather than individual pixel motion.
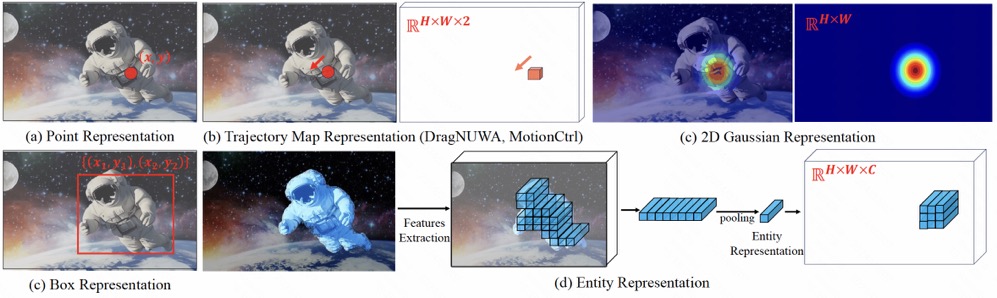
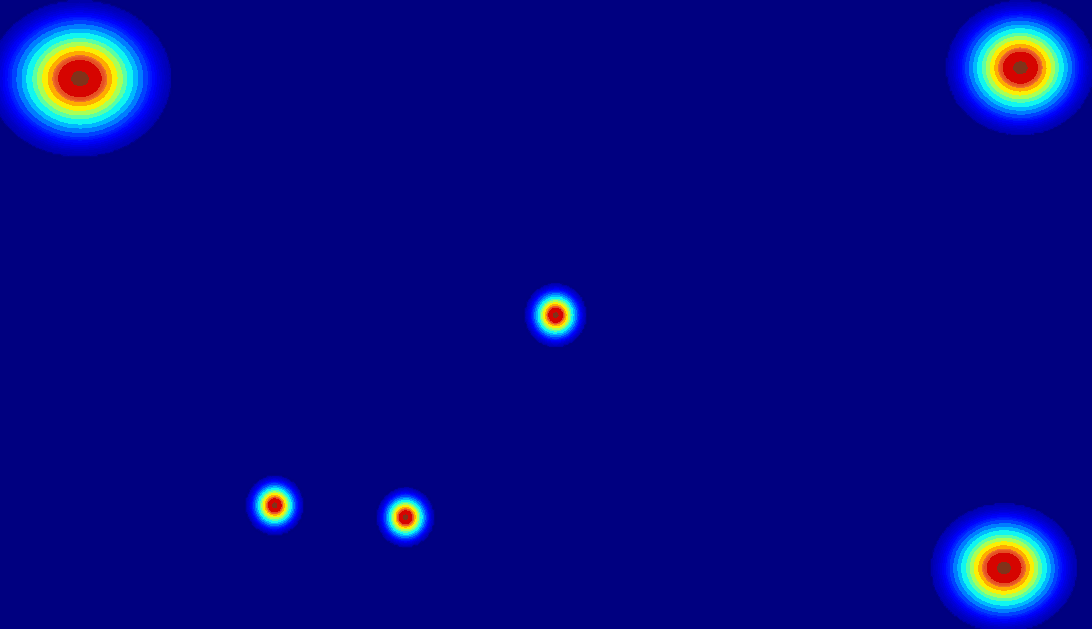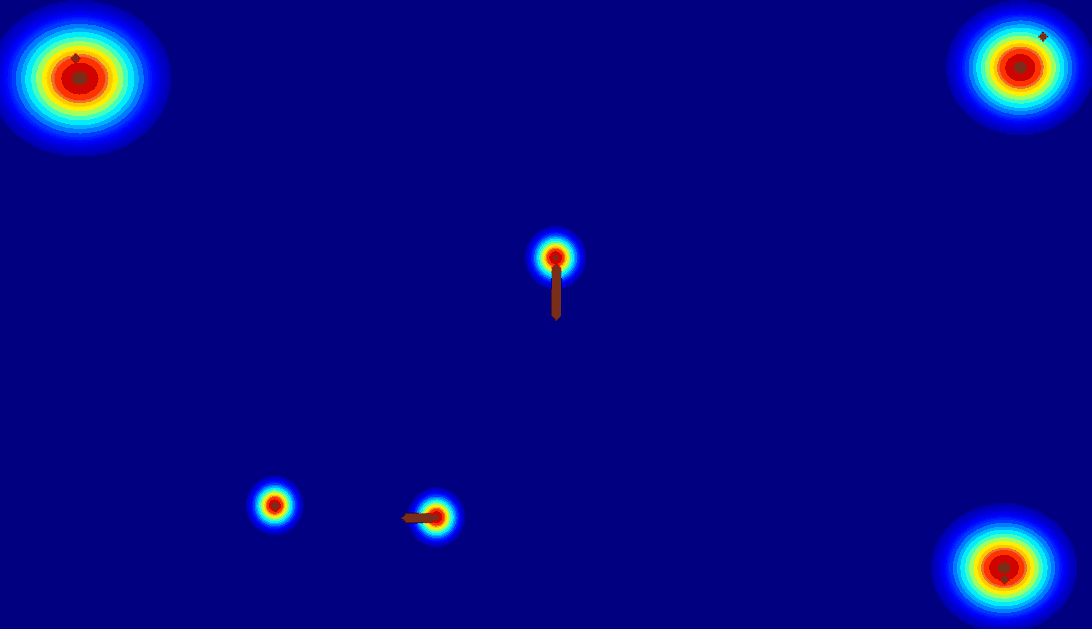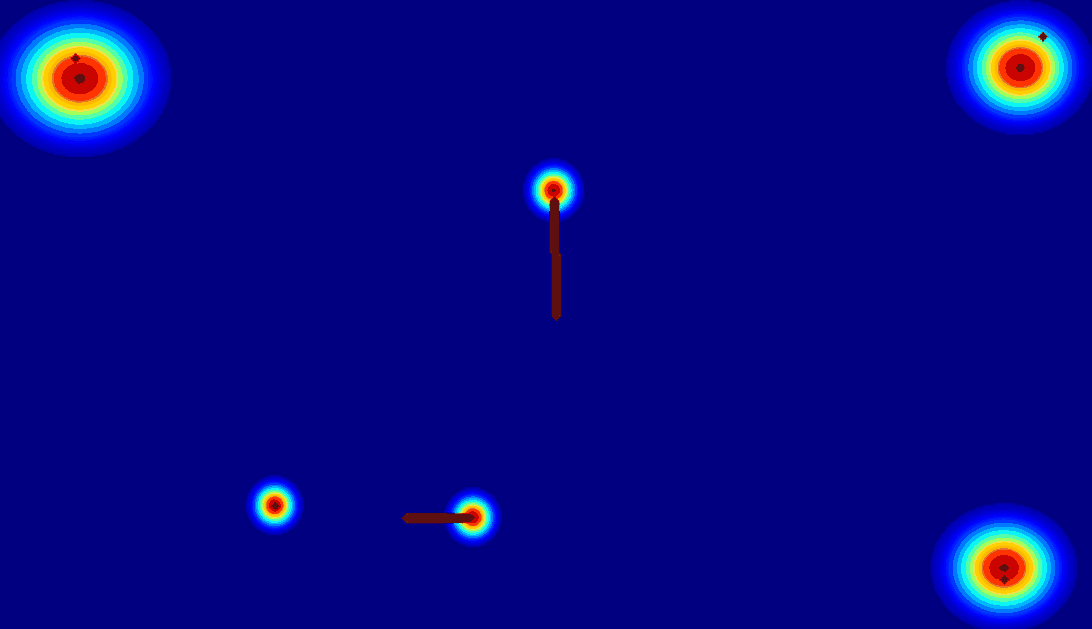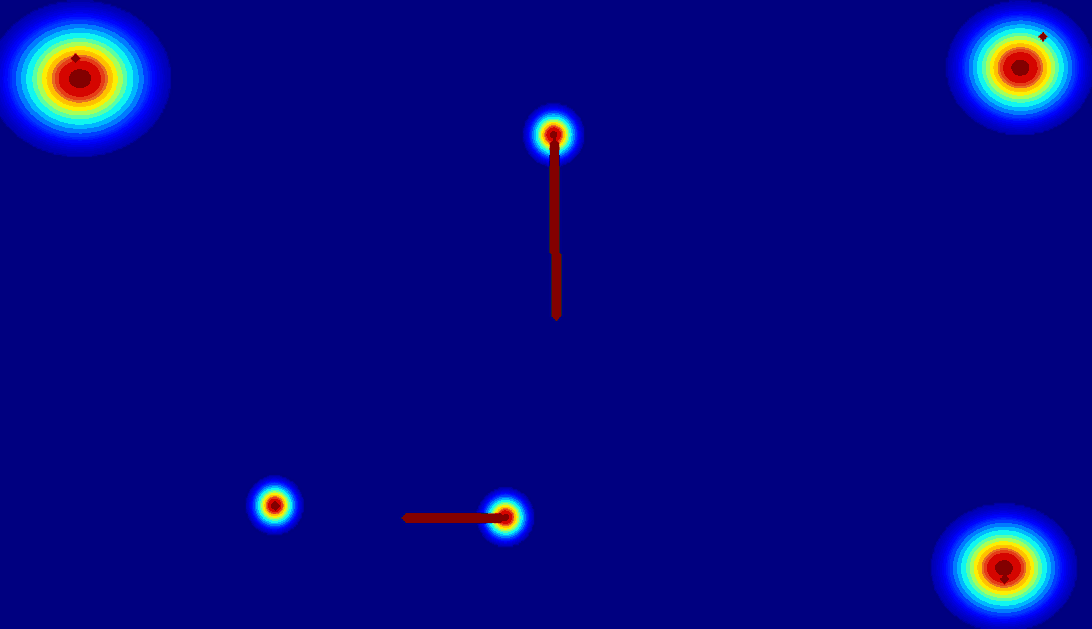
Comparison for Different Representation Modeling
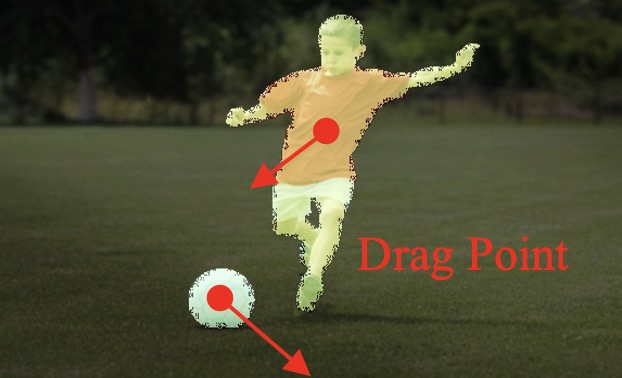
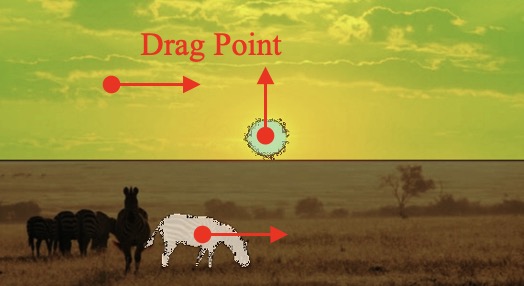
(a) Point representation:
using a coordinate point (x, y) to represent an entity.
(b) Trajectory Map:using
a trajectory vector map to represent the trajectory of the entity.
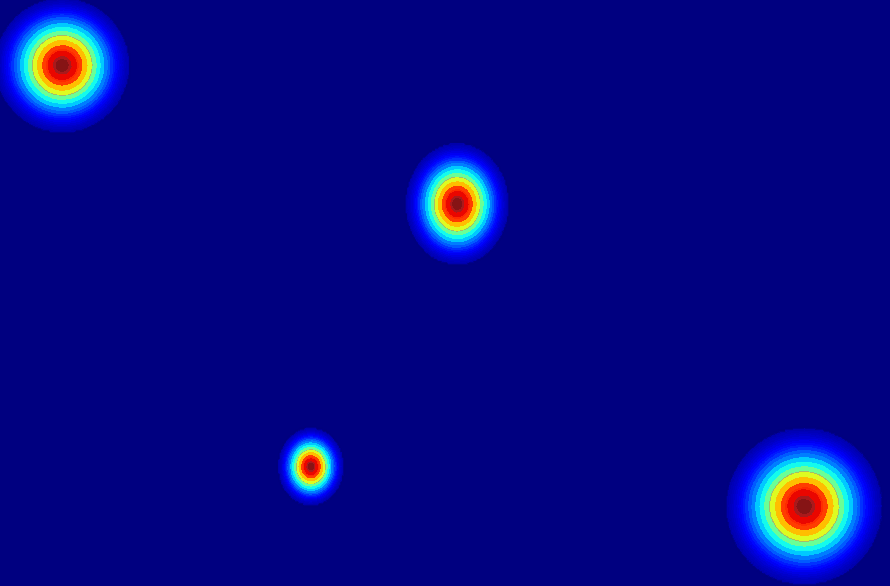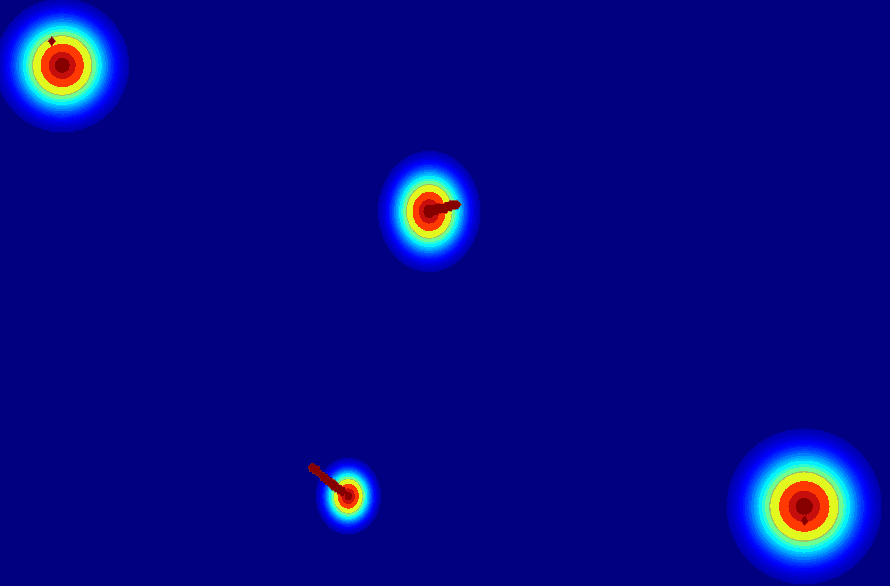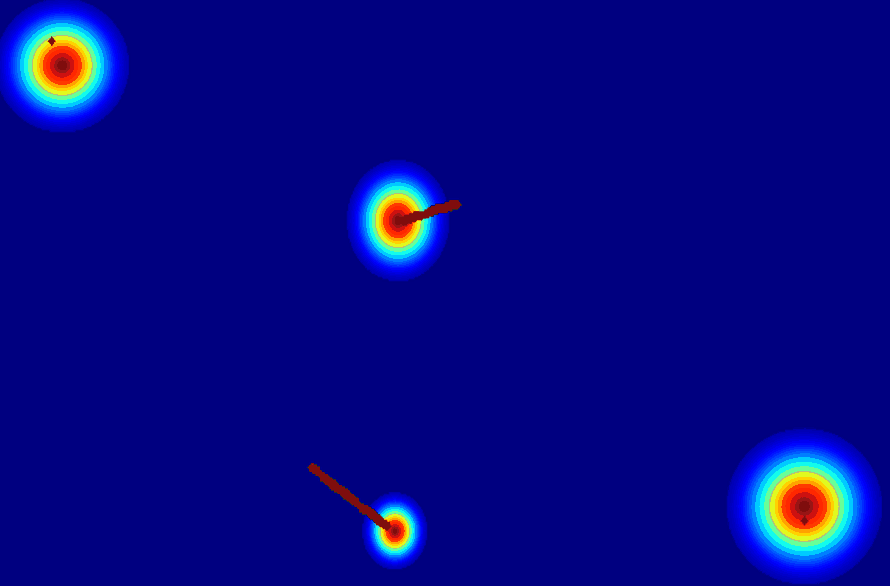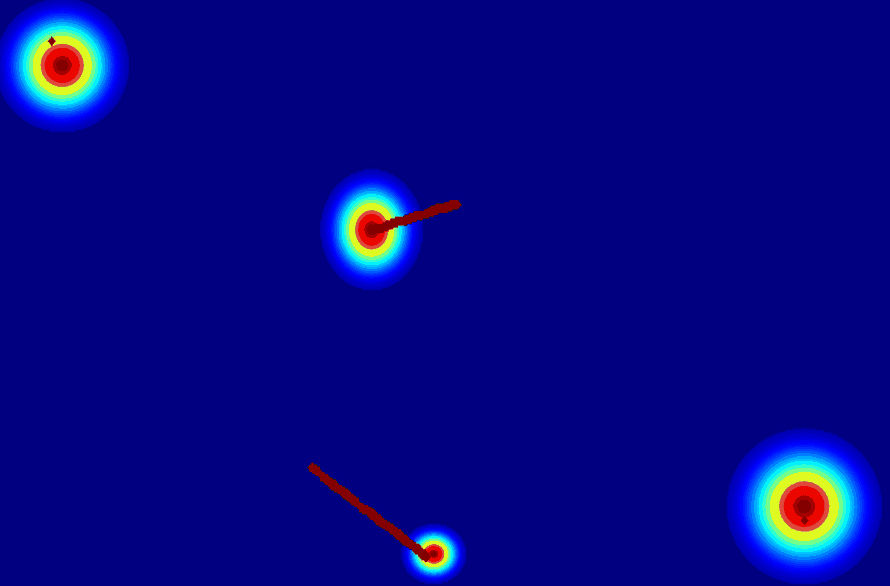
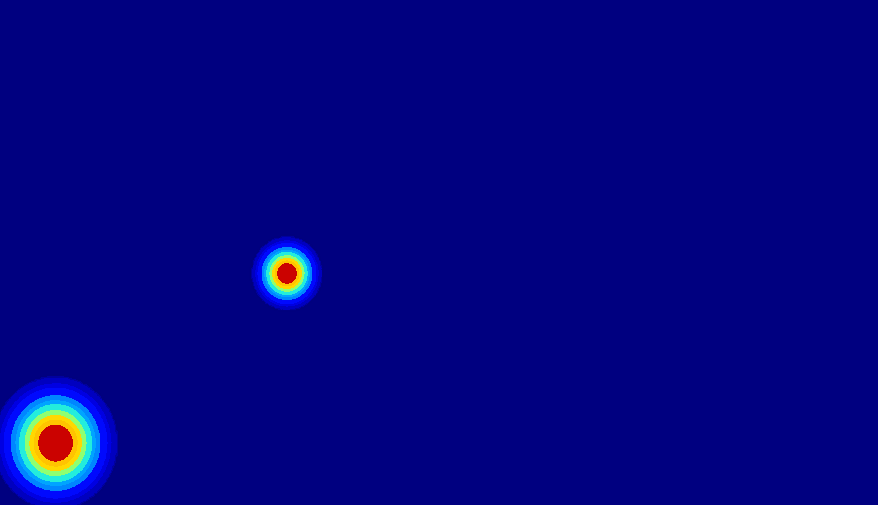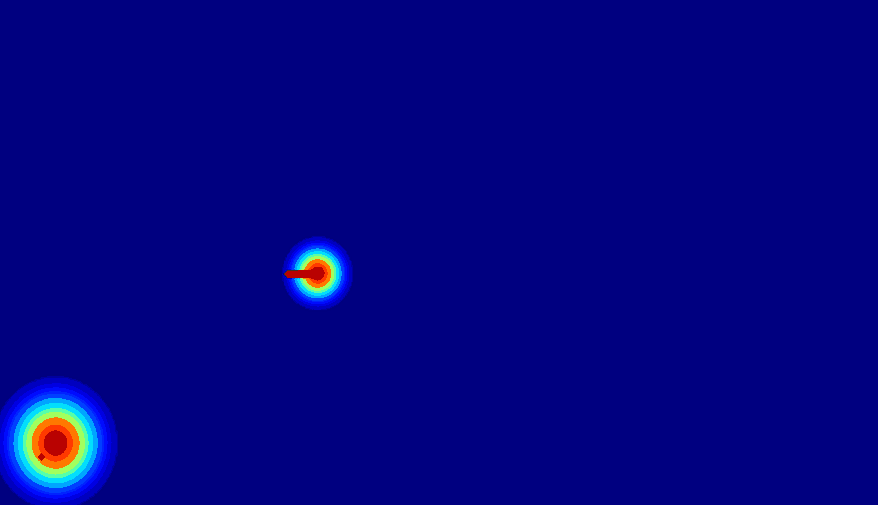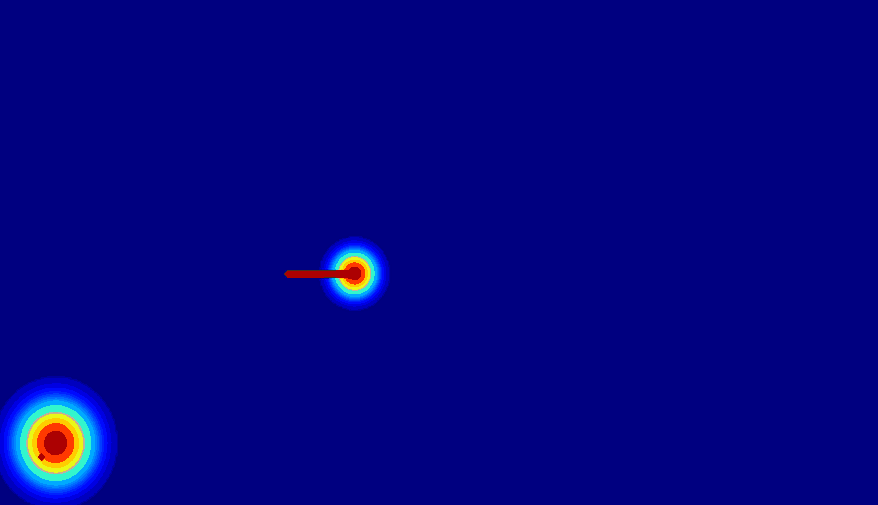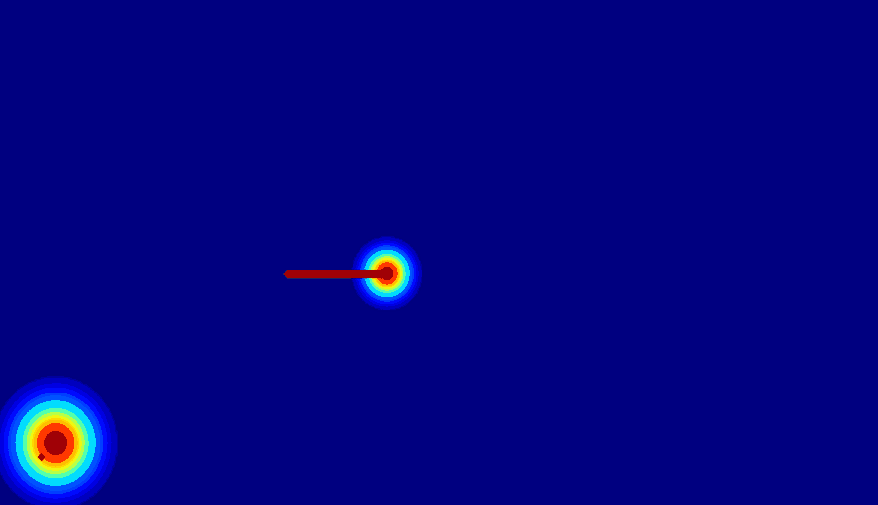
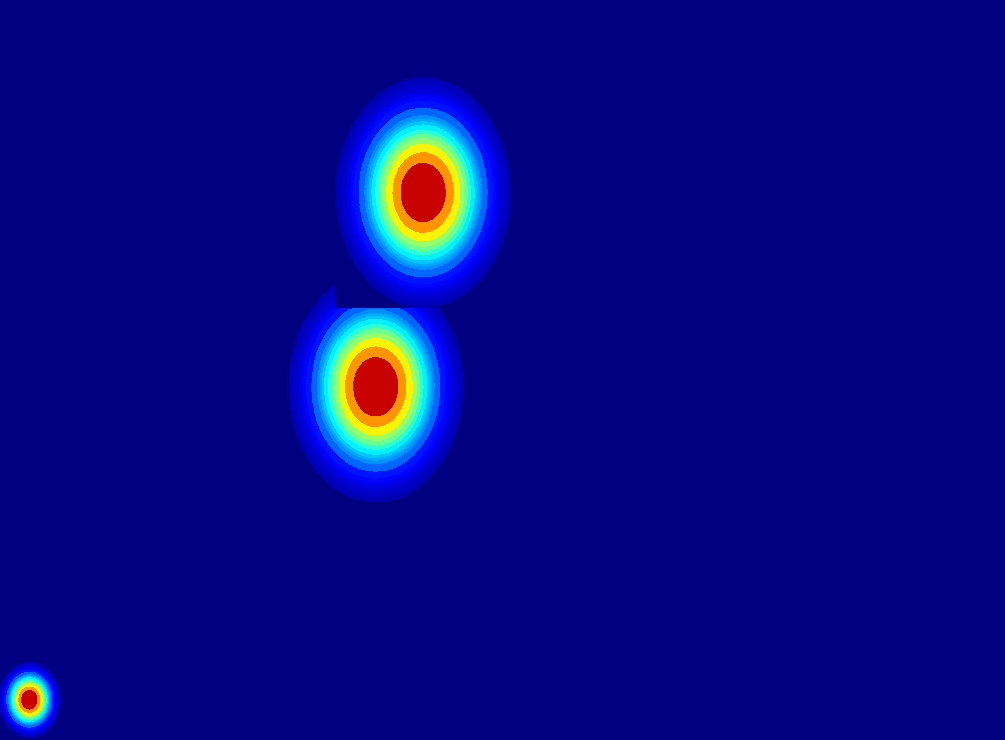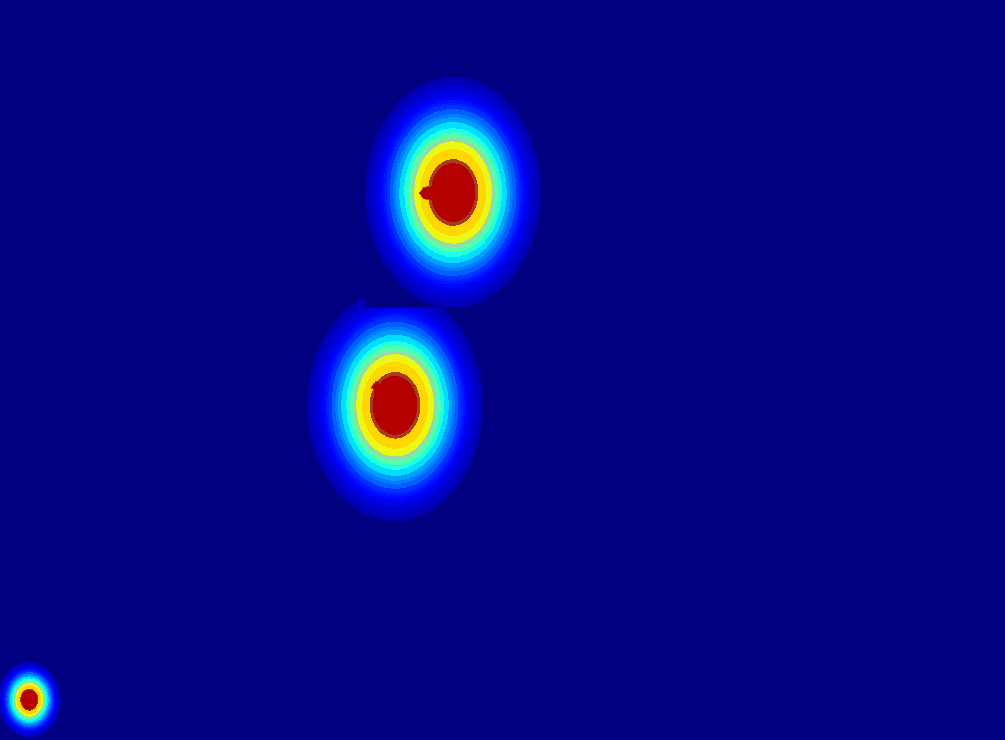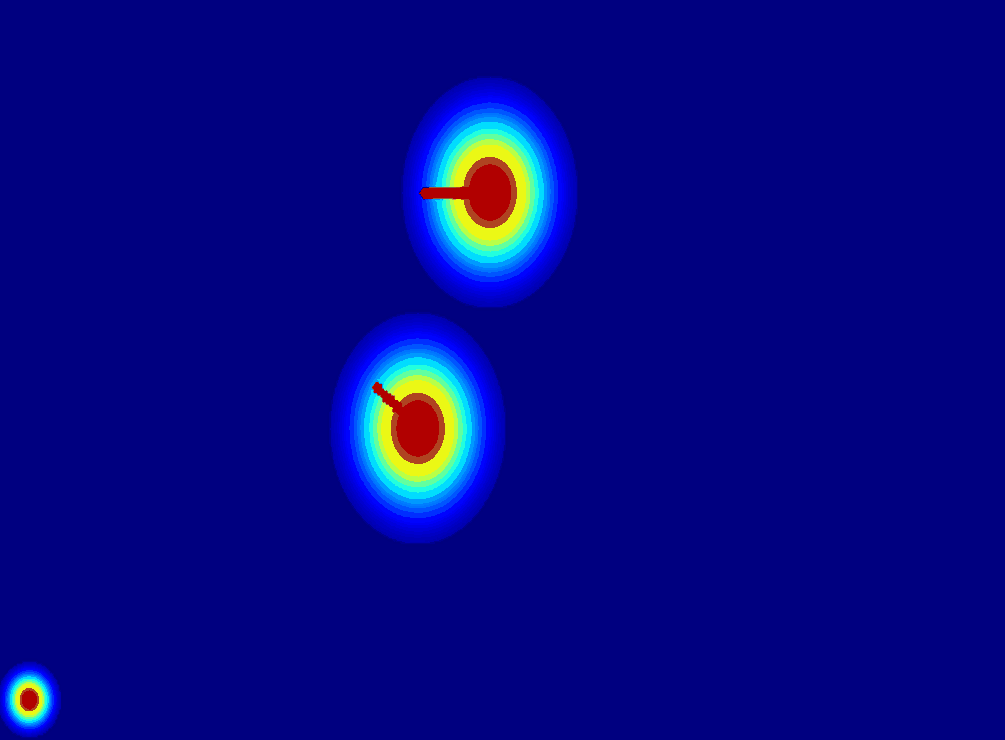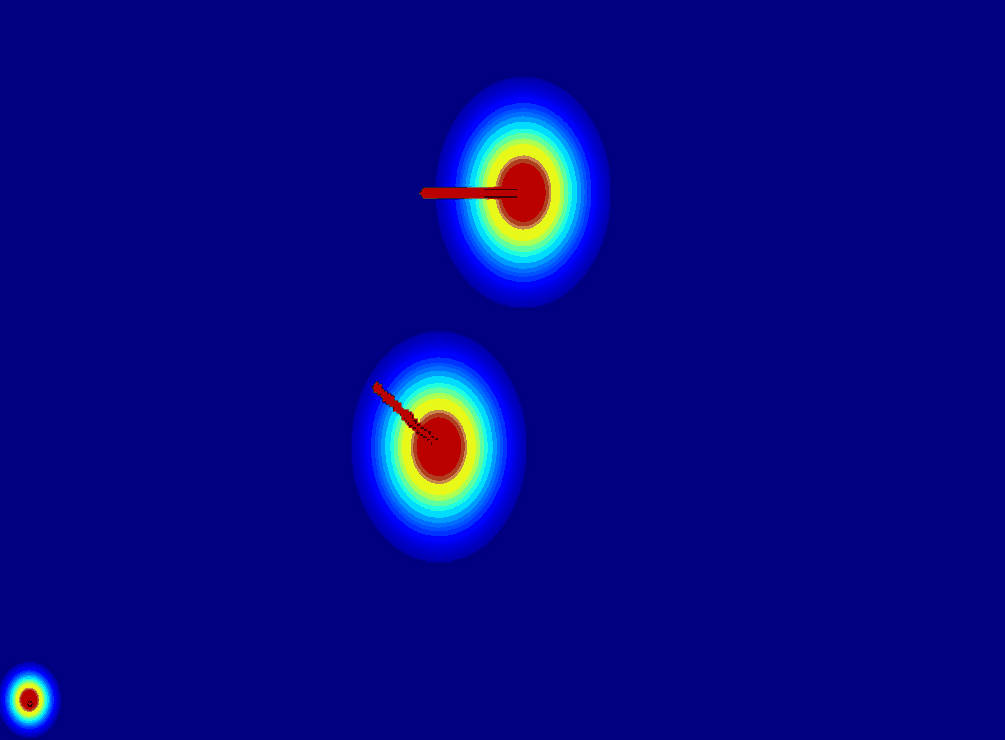
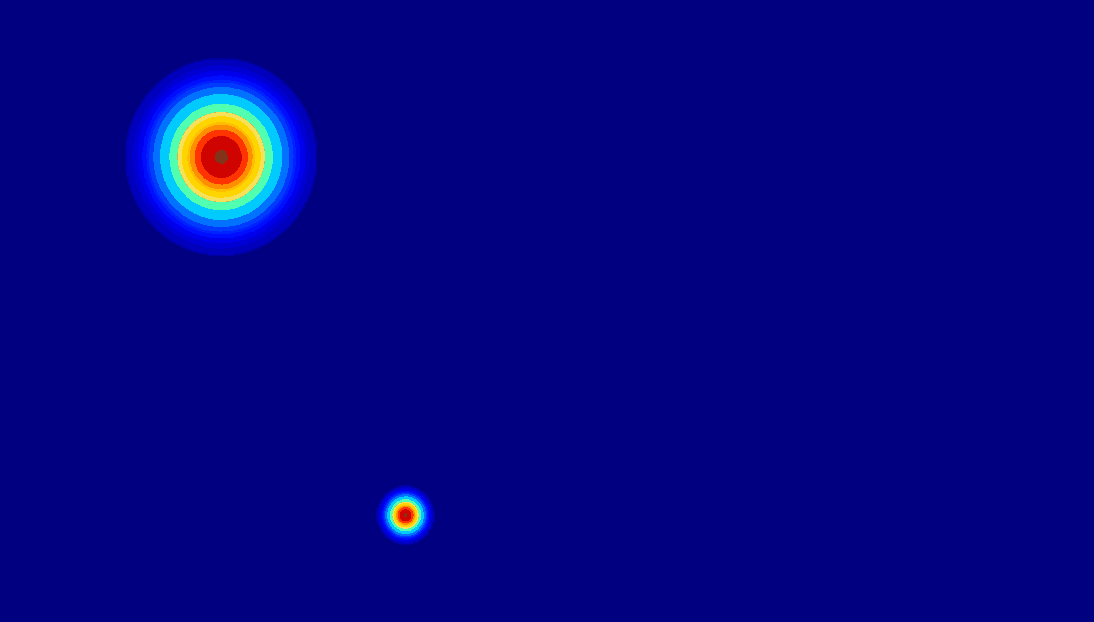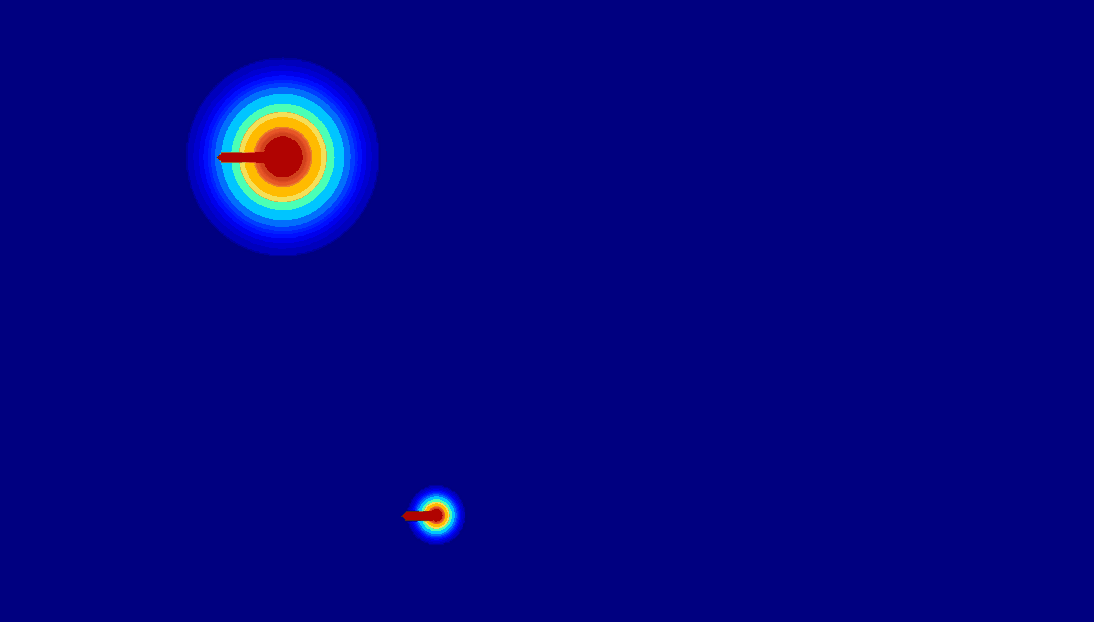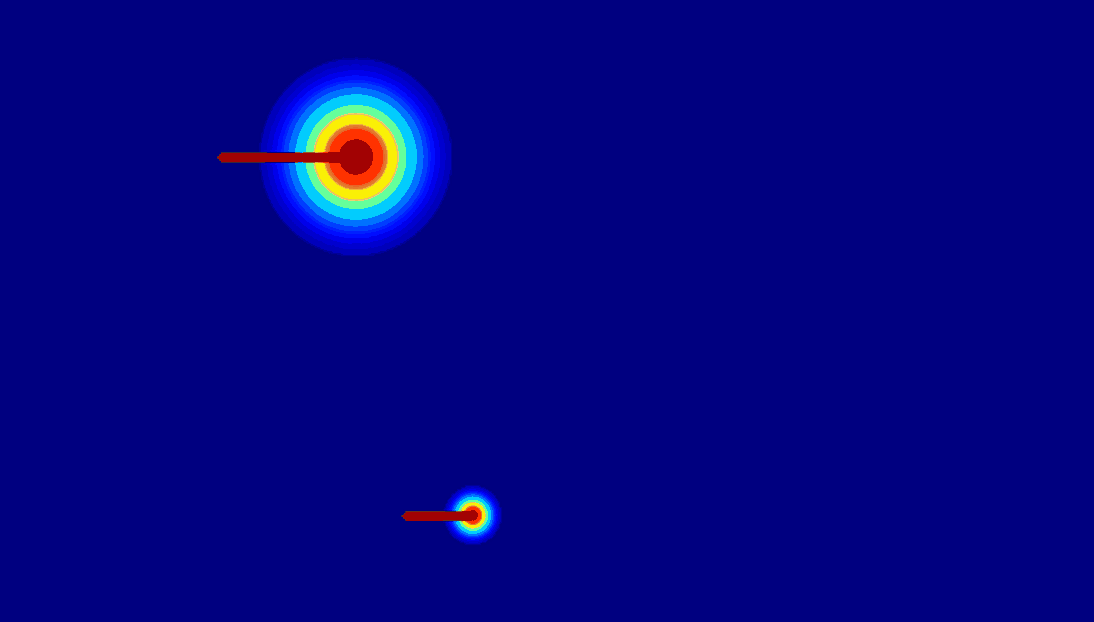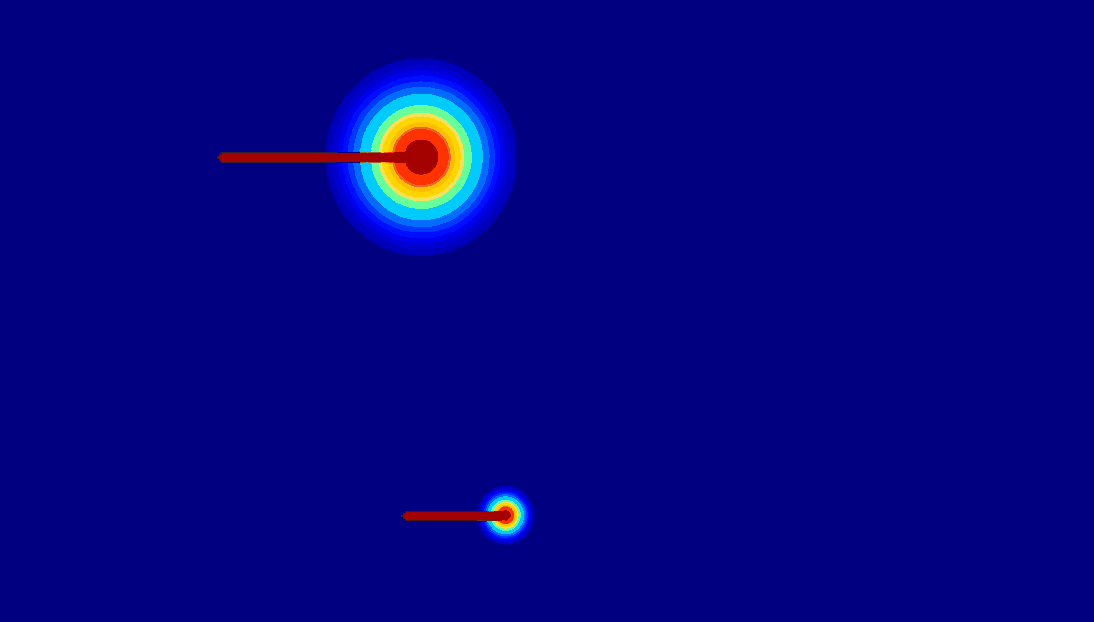
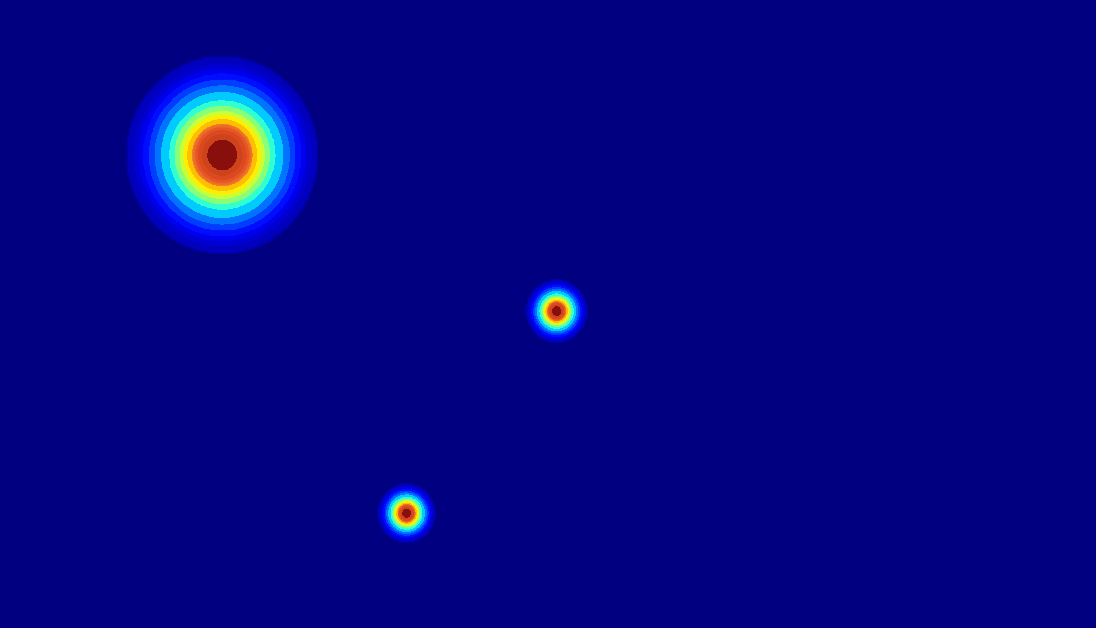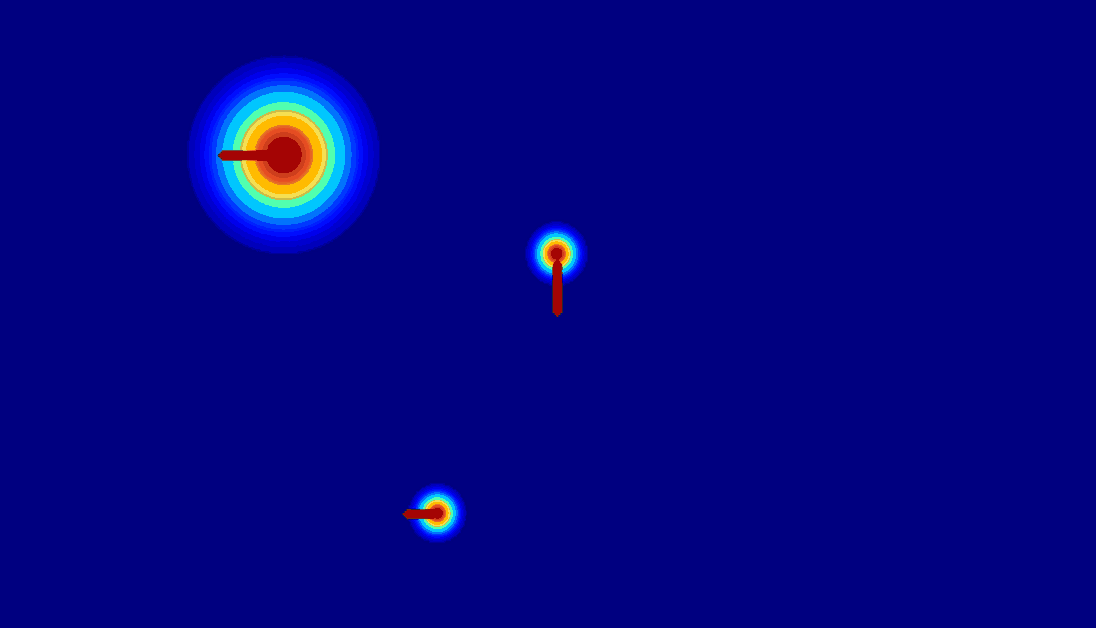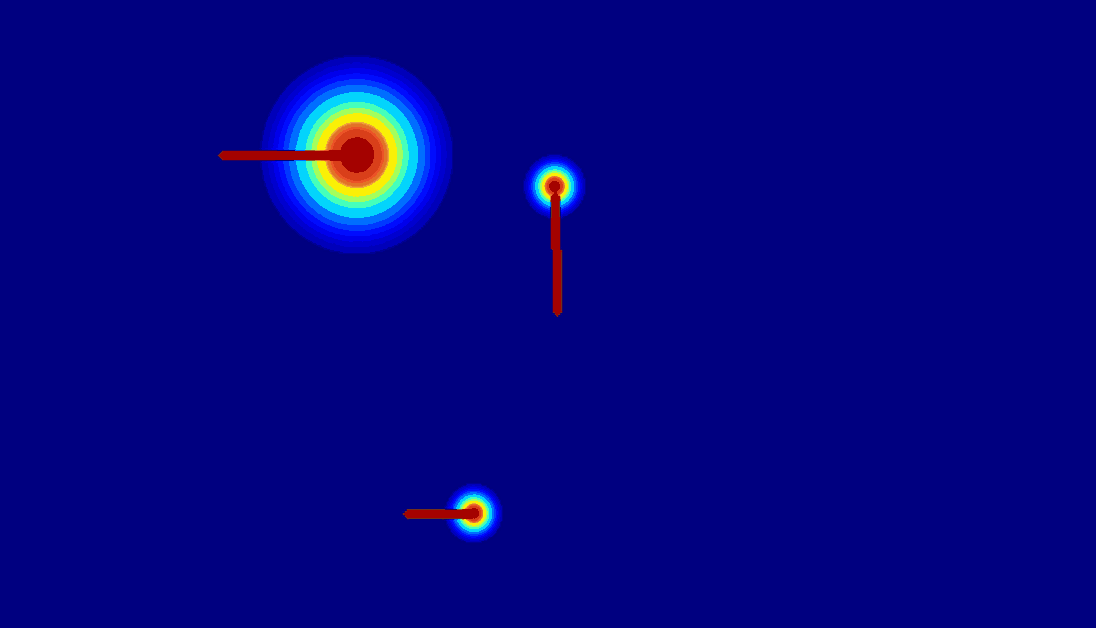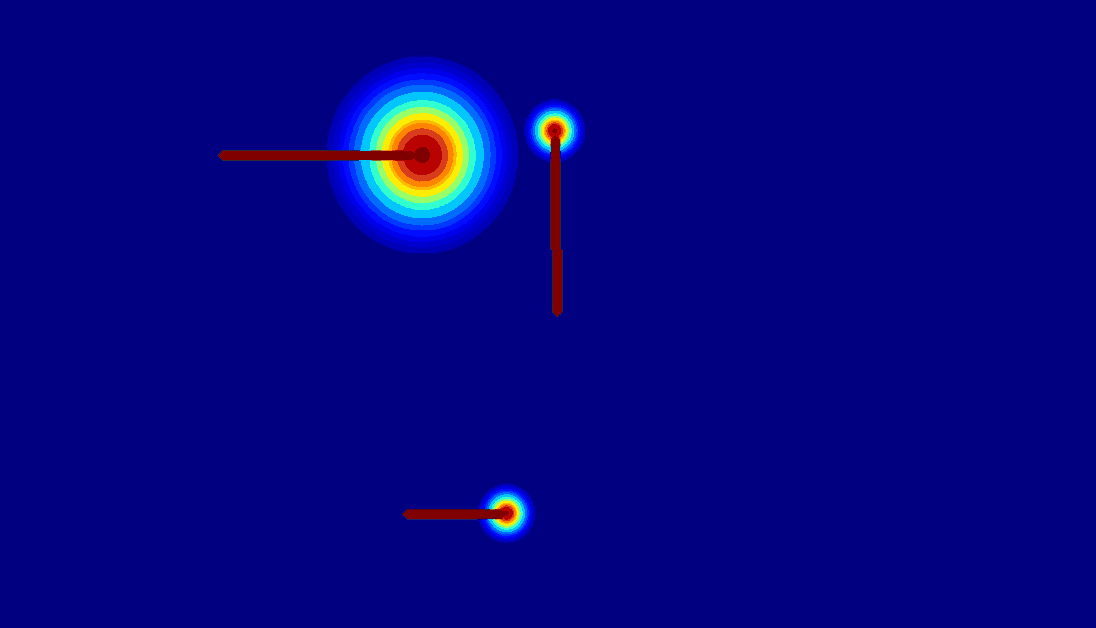
(c) 2D gaussian:using
a 2D Gaussian map to represent an entity.
(d) Entity representation:extracting the latent diffusion
feature of the entity to characterize it.
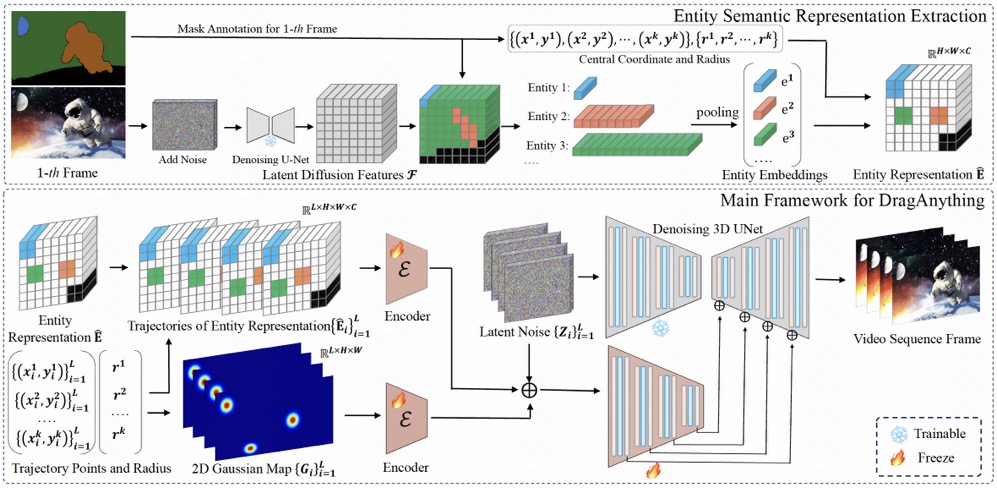
Method
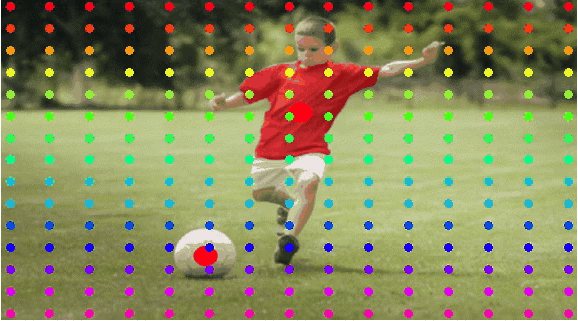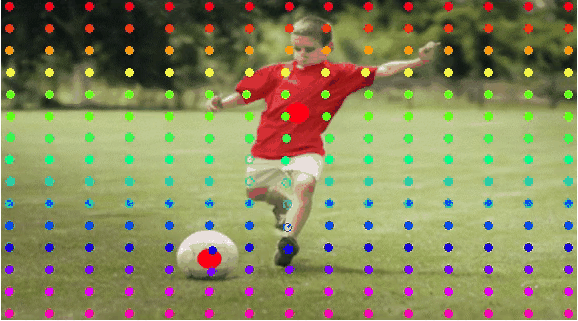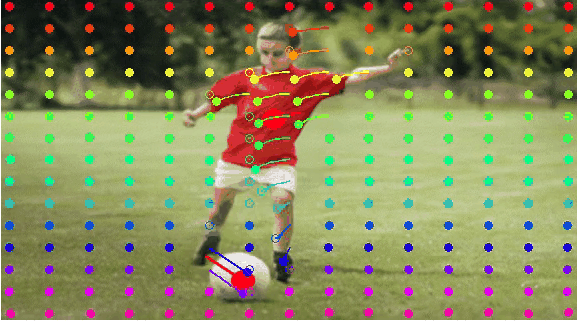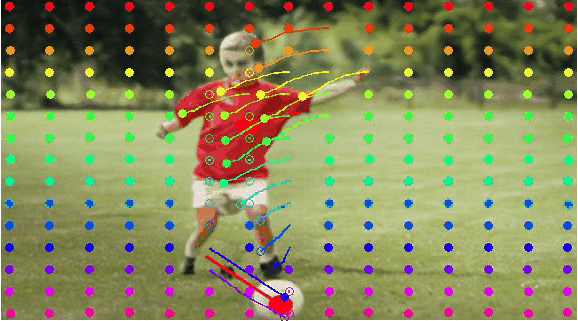
The architecture includes two parts: 1) Entity
Semantic Representation Extraction. Latent features from the Diffusion Model are extracted
based on entity mask indices to serve as corresponding entity representations. 2)
Main Framework for DragAnything. Utilizing the corresponding entity representations
and 2D Gaussian representations to control the motion of entities.
 arXiv
arXiv
 Code
Code