|
Weijia Wu
Weijia Wu is a Research Fellow at (Show Lab), National University of Singapore, working with Prof. Mike Z. Shou. He received the PhD from Zhejiang University. Additionally, he is also a popper; and has been dancing popping for five years. In the spare time, he also enjoys playing basketball and swimming.
Email /
Google Scholar /
GitHub /
Twitter /
Linkedin
|

|
|
Research Interests
My current research interests primarily focus on AI research for camera-based video production, including Video Generation/editing, controllable video generation, and long video generation.
Notes:
Feel free to contact me by Email(weijiawu96@gmail.com).
|
|
Video Text Detection/Spotting: TransDETR (IJCV 2024), DSText (ICDAR 2023 & PR 2024), BOVText (NeurIPS 2021, Dataset Track)
Synthetic Data for Perception Tasks: DiffuMask (ICCV 2023), DatasetDM (NeurIPS 2023)
Image Generation: ParaDiffusion (IJCV 2025)
Video Generation: DragAnything (ECCV 2024), Awesome-Video-Diffusion (4.5k stars), MovieBench (CVPR 2025), MovieAgent (Arxiv, Mar., 2025)
Unified Multimodal Models: Awesome Unified Multimodal Models (500+ stars), Blog--Towards Unified Multimodal Models:Trends and Insights , SelfTok
Visual Reinforcement Learning: Reinforcement Learning in Vision: A Survey (Arxiv, Aug., 2025)
|
|
Recent Updates
[Mar. 2026]: Received the Excellent Doctoral Dissertation Award of Zhejiang Province!
[Jan. 2026]:We organize CVPR 2026 Workshop on Generative AI for Storytelling (AISTORY)!
[Aug. 2025]: Invited talks at ICCV 2025 workshops on Generative AI for Storytelling! (Slides)
[Mar. 2025]: Received the Excellent Doctoral Dissertation Award of Zhejiang University!
[Mar. 2025]: One paper(ParaDiffusion) got accepted in IJCV 2025!
[Feb. 2025]: Two paper (MovieBench, ChatGen) got accepted in CVPR 2025 !
[Jan. 2025]: One paper (VimTS) got accepted in TPAMI 2025 !
[Sep. 2024]: One paper (ZipCache) got accepted in NeurIPS 2024!
[Jul. 2024]: One paper (TextVR) got accepted in Pattern Recognition 2024!
[Jul. 2024]: Three papers (DragAnything, MotionDirector (Oral), ControlCap) got accepted in ECCV 2024!
[Mar. 2024]: One paper(TransDETR) got accepted in IJCV 2024!
[Feb. 2024]: One paper (DiverGen) got accepted in CVPR 2024!
[Jan. 2024]: Got my Ph.D. degree from Zhejiang University!
[Jan. 2024]: One paper (EfficientDM) got accepted in ICLR 2024 (spotlight)!
[Nov. 2023]: One paper (DSText V2) got accepted in Pattern Recognition 2024!
[Nov. 2023]: One paper (CisDQ) got accepted in IEEE TCSVT 2023!
[Sep 2023]: Three papers (DatasetDM, Mix-of-Show, PTQD) got accepted in NeurIPS 2023!
[July 2023]: Three papers (DiffuMask, GenPromp, BiViT) got accepted in ICCV 2023!
[Dec. 2022]:We organize LOng-form VidEo Understanding and Generation Workshop & International Challenge @ CVPR'23!
[Dec. 2022]:We organize ICDAR2023 Video Text Reading Competition for Dense and Small Text!
[June 2022]: One paper got accepted in ICIP 2022!
[March 2022]:Serve as a reviewer for ICML2022.
[July 2021]: One paper got accepted in NeurIPS 2021!!
[June 2021]:Serve as a reviewer for NeurIPS2021.
|
|
Experience
[January 2021 - January 2022]:Research Intern at MMU, KuaiShou, led by Debing Zhang
[January 2022 - August 2023]:Research Intern at MMU, KuaiShou, led by Jiahong Li
[August 2022 - August 2023]:Visting PhD student at Show lab, NUS, led by Asst Prof. Mike Shou
[Dec. 2023 - Present]:Research Fellow at Show lab, NUS, work with Asst Prof. Mike Shou
|
|
Selected Publications (* Equal, # Corresponding)
|
|
|
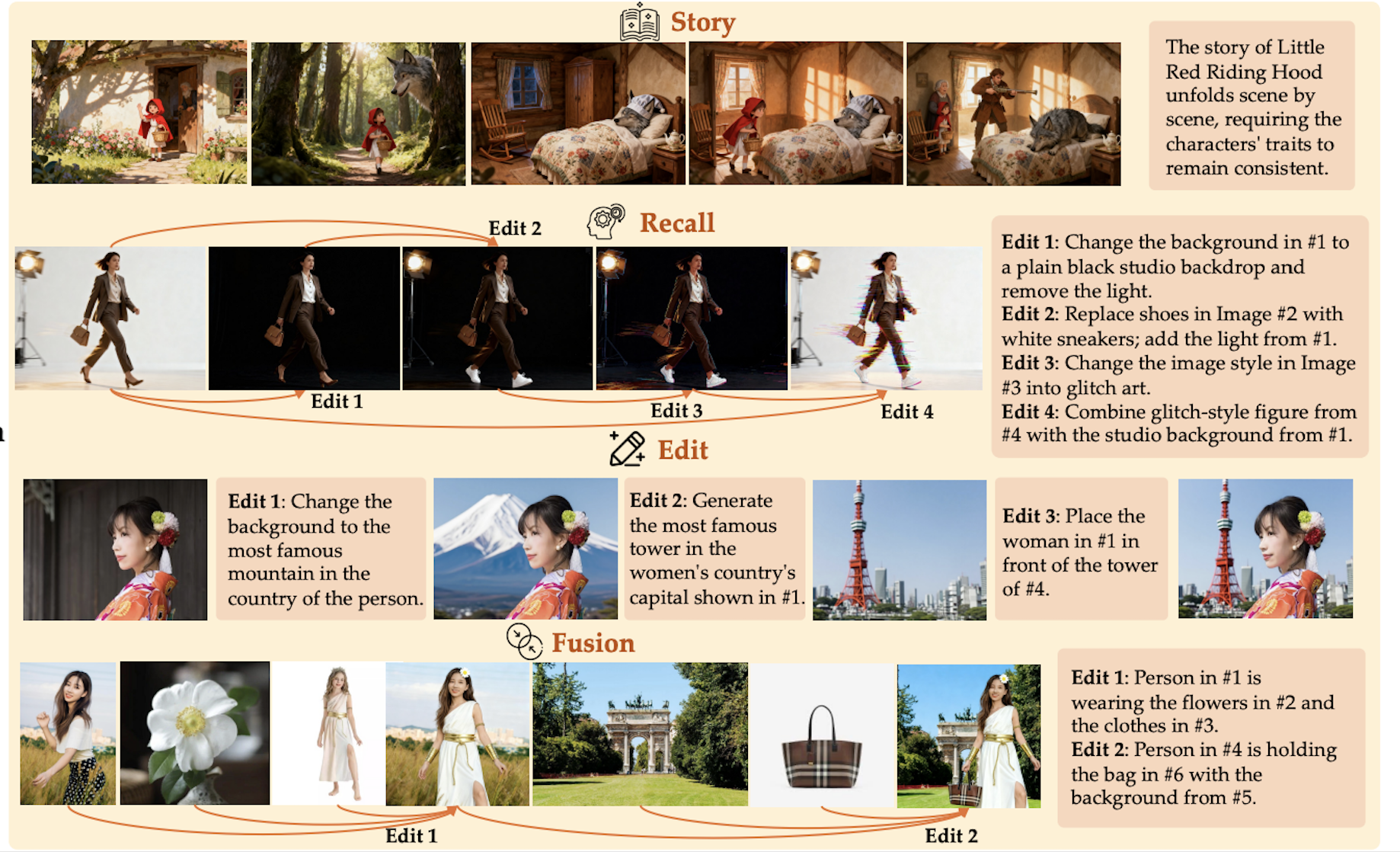
WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
Wei Chow, Jiachun Pan, Yongyuan Liang, Mingze Zhou, Xue Song, Liyu Jia, Saining Zhang, Siliang Tang, Juncheng Li, Fengda Zhang#, Weijia Wu#, Hanwang Zhang, Tat-Seng Chua .
IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2026),
Abstract /
arXiv /
BibTex /
GitHub /
Huggingface /
Project Page /
Twitter(X) /
Recent advances in unified multimodal models (UMMs) have enabled impressive progress in visual comprehension and generation. However, existing datasets and benchmarks focus primarily on single-turn interactions, failing to capture the multi-turn, context-dependent nature of real-world image creation and editing. To address this gap, we present WEAVE, the first suite for in-context interleaved cross-modality comprehension and generation. Our suite consists of two complementary parts. WEAVE-100k is a large-scale dataset of 100K interleaved samples spanning over 370K dialogue turns and 500K images, covering comprehension, editing, and generation tasks that require reasoning over historical context. WEAVEBench is a human-annotated benchmark with 100 tasks based on 480 images, featuring a hybrid VLM judger evaluation framework based on both the reference image and the combination of the original image with editing instructions that assesses models' abilities in multi-turn generation, visual memory, and world-knowledge reasoning across diverse domains. Experiments demonstrate that training on WEAVE-100k enables vision comprehension, image editing, and comprehension-generation collaboration capabilities. Furthermore, it facilitates UMMs to develop emergent visual-memory capabilities, while extensive evaluations on WEAVEBench expose the persistent limitations and challenges of current approaches in multi-turn, context-aware image generation and editing. We believe WEAVE provides a view and foundation for studying in-context interleaved comprehension and generation for multi-modal community.
@article{chow2025weave,
title={WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation},
author={Chow, Wei and Pan, Jiachun and Liang, Yongyuan and Zhou, Mingze and Song, Xue and Jia, Liyu and Zhang, Saining and Tang, Siliang and Li, Juncheng and Zhang, Fengda and others},
journal={IEEE Conference on Computer Vision and Pattern Recognition},
year={2026}
}
|
|
|
Paragraph-to-Image Generation with Information-Enriched Diffusion Model
Weijia Wu, Zhuang Li, Yefei He, Mike Zheng Shou, Chunhua Shen, Lele Cheng,Yan Li, Tingting Gao,Zhang Di.
International Journal of Computer Vision (IJCV),
Abstract /
arXiv /
BibTex /
GitHub /
Project Page /
Twitter(X) /
Text-to-image (T2I) models have recently experienced rapid development, achieving astonishing performance in terms of fidelity and textual alignment capabilities. However, given a long paragraph (up to 512 words), these generation models still struggle to achieve strong alignment and are unable to generate images depicting complex scenes. In this paper, we introduce an information-enriched diffusion model for paragraph-to-image generation task, termed ParaDiffusion, which delves into the transference of the extensive semantic comprehension capabilities of large language models to the task of image generation. At its core is using a large language model (e.g., Llama V2) to encode long-form text, followed by fine-tuning with LORA to alignthe text-image feature spaces in the generation task. To facilitate the training of long-text semantic alignment, we also curated a high-quality paragraph-image pair dataset, namely ParaImage. This dataset contains a small amount of high-quality, meticulously annotated data, and a large-scale synthetic dataset with long text descriptions being generated using a vision-language model. Experiments demonstrate that ParaDiffusion outperforms state-of-the-art models (SD XL, DeepFloyd IF) on ViLG-300 and ParaPrompts, achieving up to 15% and 45% human voting rate improvements for visual appeal and text faithfulness, respectively. The code and dataset will be released to foster community research on long-text alignment.
@article{wu2025paragraph,
title={Paragraph-to-image generation with information-enriched diffusion model},
author={Wu, Weijia and Li, Zhuang and He, Yefei and Shou, Mike Zheng and Shen, Chunhua and Cheng, Lele and Li, Yan and Gao, Tingting and Zhang, Di and Wang, Zhongyuan},
journal={International Journal of Computer Vision},
year={2025}
}
|
|
|
MovieBench: A Hierarchical Movie Level Dataset for Long Video Generation
Weijia Wu, Mingyu Liu, Zeyu Zhu, Xi Xia, Haoen Feng, Wen Wang, Kevin Qinghong Lin, Chunhua Shen, Mike Zheng Shou.
IEEE Conference on Computer Vision and Pattern Recognition(CVPR 2025),
Abstract /
arXiv /
BibTex /
GitHub /
Project Page /
Twitter(X) /
Recent advancements in video generation models, like Stable Video Diffusion, show promising results, but primarily focus on short, single-scene videos. These models struggle with generating long videos that involve multiple scenes, coherent narratives, and consistent characters. Furthermore, there is no publicly available dataset tailored for the analysis, evaluation, and training of long video generation models. In this paper, we present MovieBench: A Hierarchical Movie-Level Dataset for Long Video Generation, which addresses these challenges by providing unique contributions: (1) movie-length videos featuring rich, coherent storylines and multi-scene narratives, (2) consistency of character appearance and audio across scenes, and (3) hierarchical data structure contains high-level movie information and detailed shot-level descriptions. Experiments demonstrate that MovieBench brings some new insights and challenges, such as maintaining character ID consistency across multiple scenes for various characters. The dataset will be public and continuously maintained, aiming to advance the field of long video generation. Data can be found at: https://weijiawu.github.io/MovieBench/.
@article{wu2024moviebench,
title={MovieBench: A Hierarchical Movie Level Dataset for Long Video Generation},
author={Wu, Weijia and Liu, Mingyu and Zhu, Zeyu and Xia, Xi and Feng, Haoen and Wang, Wen and Lin, Kevin Qinghong and Shen, Chunhua and Shou, Mike Zheng},
journal={IEEE Conference on Computer Vision and Pattern Recognition},
year={2025}
}
|
|
|
DragAnything: Motion Control for Anything using Entity Representation
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, Di Zhang.
The 18th European Conference on Computer Vision(ECCV 2024),
Abstract /
arXiv /
BibTex /
GitHub /
Project Page /
Twitter(X) /
We introduce DragAnything, which utilizes a entity representation to achieve motion control for any object in controllable video
generation. Comparison to existing motion control methods, DragAnything offers several advantages. Firstly, trajectory-based is more userfriendly for interaction, when acquiring other guidance signals (e.g.,
masks, depth maps) is labor-intensive. Users only need to draw a line (trajectory) during interaction. Secondly, our entity representation serves as
an open-domain embedding capable of representing any object, enabling
the control of motion for diverse entities, including background. Lastly,
our entity representation allows simultaneous and distinct motion control for multiple objects. Extensive experiments demonstrate that our
DragAnything achieves state-of-the-art performance for FVD, FID, and
User Study, particularly in terms of object motion control, where our
method surpasses the previous methods (e.g., DragNUWA) by 26% in
human voting.
@article{wu2024draganything,
title={DragAnything: Motion Control for Anything using Entity Representation},
author={Wu, Wejia and Li, Zhuang and Gu, Yuchao and Zhao, Rui and He, Yefei and Zhang, David Junhao and Shou, Mike Zheng and Li, Yan and Gao, Tingting and Zhang, Di},
journal={The 18th European Conference on Computer Vision (ECCV 2024)},
year={2024}
}
|
|
|
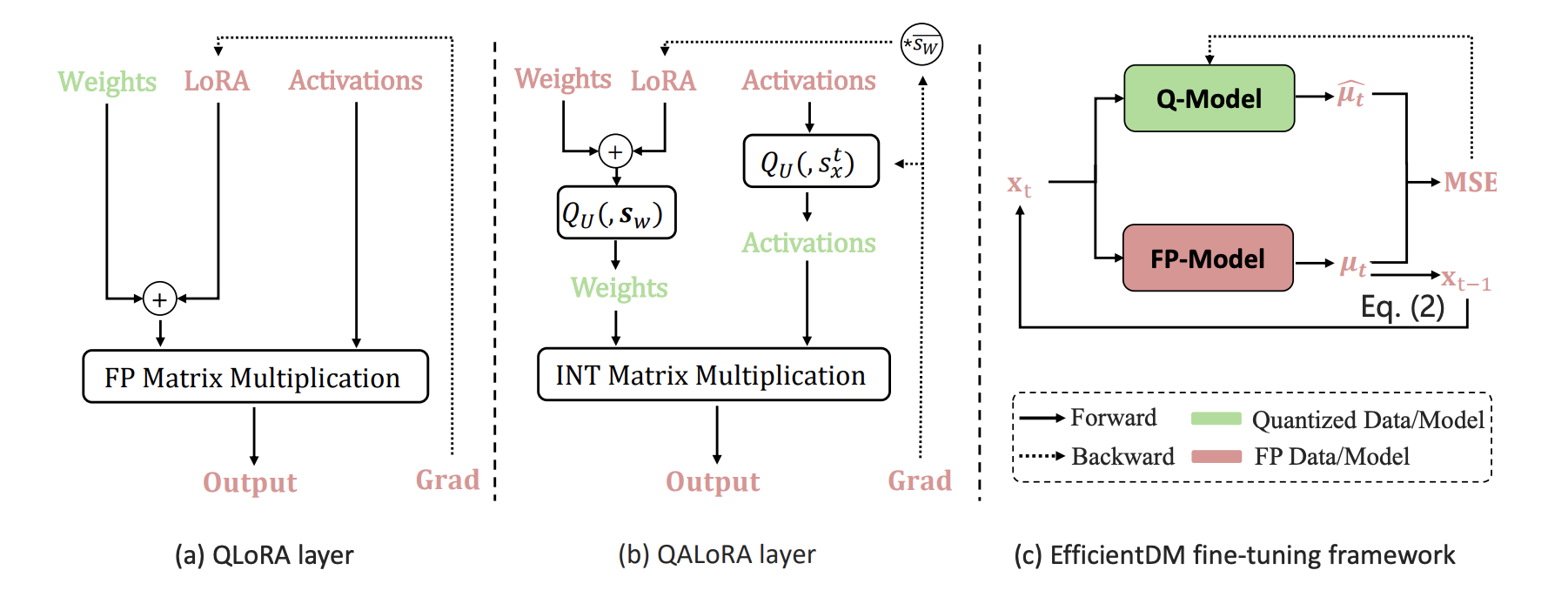
EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models
Yefei He, Jing Liu, Weijia Wu, Hong Zhou, Bohan Zhuang.
The Twelfth International Conference on Learning Representations(ICLR 2024 spotlight),
Abstract /
arXiv /
BibTex /
Diffusion models have demonstrated remarkable capabilities in image synthesis and related generative tasks. Nevertheless, their practicality for low-latency
real-world applications is constrained by substantial computational costs and latency issues. Quantization is a dominant way to compress and accelerate diffusion
models, where post-training quantization (PTQ) and quantization-aware training
(QAT) are two main approaches, each bearing its own properties. While PTQ exhibits efficiency in terms of both time and data usage, it may lead to diminished
performance in low bit-width settings. On the other hand, QAT can help alleviate performance degradation but comes with substantial demands on computational and data resources. To capitalize on the advantages while avoiding their respective drawbacks, we introduce a data-free, quantization-aware and parameterefficient fine-tuning framework for low-bit diffusion models, dubbed EfficientDM,
to achieve QAT-level performance with PTQ-like efficiency. Specifically, we propose a quantization-aware variant of the low-rank adapter (QALoRA) that can
be merged with model weights and jointly quantized to low bit-width. The finetuning process distills the denoising capabilities of the full-precision model into
its quantized counterpart, eliminating the requirement for training data. To further
enhance performance, we introduce scale-aware optimization to address ineffective learning of QALoRA due to variations in weight quantization scales across
different layers. We also employ temporal learned step-size quantization to handle
notable variations in activation distributions across denoising steps. Extensive experimental results demonstrate that our method significantly outperforms previous
PTQ-based diffusion models while maintaining similar time and data efficiency.
Specifically, there is only a marginal 0.05 sFID increase when quantizing both
weights and activations of LDM-4 to 4-bit on ImageNet 256 × 256. Compared
to QAT-based methods, our EfficientDM also boasts a 16.2× faster quantization
speed with comparable generation quality, rendering it a compelling choice for
practical applications.
@article{he2023efficientdm,
title={EfficientDM: Efficient Quantization-Aware Fine-Tuning of Low-Bit Diffusion Models},
author={He, Yefei and Liu, Jing and Wu, Weijia and Zhou, Hong and Zhuang, Bohan},
journal={The Twelfth International Conference on Learning Representations (ICLR 2024)},
year={2024}
}
|
|
|
PTQD: Accurate Post-Training Quantization for Diffusion Models†
Yefei He, Luping Liu, Jing Liu, Weijia Wu, Hong Zhou, Bohan Zhuang.
Thirty-seventh Conference on Neural Information Processing Systems(NeurIPS 2023),
Abstract /
arXiv /
BibTex /
Diffusion models have recently dominated image synthesis and other related generative tasks. However, the iterative denoising process is expensive in computations at inference time, making diffusion models less practical for low-latency and scalable real-world applications. Post-training quantization of diffusion models can significantly reduce the model size and accelerate the sampling process without requiring any re-training. Nonetheless, applying existing post-training quantization methods directly to low-bit diffusion models can significantly impair the quality of generated samples. Specifically, for each denoising step, quantization noise leads to deviations in the estimated mean and mismatches with the predetermined variance schedule. Moreover, as the sampling process proceeds, the quantization noise may accumulate, resulting in a low signal-to-noise ratio (SNR) in late denoising steps. To address these challenges, we propose a unified formulation for the quantization noise and diffusion perturbed noise in the quantized denoising process. We first disentangle the quantization noise into its correlated and residual uncorrelated parts regarding its full-precision counterpart. The correlated part can be easily corrected by estimating the correlation coefficient. For the uncorrelated part, we calibrate the denoising variance schedule to absorb the excess variance resulting from quantization. Moreover, we propose a mixed-precision scheme to choose the optimal bitwidth for each denoising step, which prefers low bits to accelerate the early denoising steps while high bits maintain the high SNR for the late steps.
@article{he2023ptqd,
title={PTQD: Accurate Post-Training Quantization for Diffusion Models},
author={He, Yefei and Liu, Luping and Liu, Jing and Wu, Weijia and Zhou, Hong and Zhuang, Bohan},
journal={Proc. Advances In Neural Information Processing Systems (NeurIPS 2023)},
year={2023}
}
|
|
|
DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models
Weijia Wu, Yuzhong Zhao, Hao Chen, Yuchao Gu, Rui Zhao, Yefei He, Hong Zhou, Mike Zheng Shou, Chunhua Shen.
Thirty-seventh Conference on Neural Information Processing Systems(NeurIPS 2023),
Abstract /
arXiv /
BibTex /
GitHub /
Project Page /
中文公众号报道 /
Current deep networks are very data-hungry and benefit from training on largescale datasets, which are often time-consuming to collect and annotate. By contrast, synthetic data can be generated infinitely using generative models such as DALL-E and diffusion models, with minimal effort and cost. In this paper, we present DatasetDM, a generic dataset generation model that can produce diverse synthetic images and the corresponding high-quality perception annotations (e.g., segmentation masks, and depth). Our method builds upon the pre-trained diffusion model and extends text-guided image synthesis to perception data generation. We show that the rich latent code of the diffusion model can be effectively decoded as accurate perception annotations using a decoder module. Training the decoder only needs less than 1% (around 100 images) manually labeled images, enabling the generation of an infinitely large annotated dataset. Then these synthetic data can be used for training various perception models for downstream tasks. To showcase the power of the proposed approach, we generate datasets with rich dense pixel-wise labels for a wide range of downstream tasks, including semantic segmentation, instance segmentation, and depth estimation. Notably, it achieves 1) state-of-the-art results on semantic segmentation and instance segmentation; 2) significantly more robust on domain generalization than using the real data alone; and state-of-the-art results in zero-shot segmentation setting; and 3) flexibility for efficient application and novel task composition (e.g., image editing).
@article{wu2023datasetdm,
title={DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models},
author={Wu, Weijia and Zhao, Yuzhong and Chen, Hao and Gu, Yuchao and Zhao, Rui and He, Yefei and Zhou, Hong and Shou, Mike Zheng and Shen, Chunhua},
journal={Proc. Advances In Neural Information Processing Systems (NeurIPS 2023)},
year={2023}
}
|
|
|
BiViT: Extremely Compressed Binary Vision Transformers
Yefei He,Zhenyu Lou,,Luoming Zhang Weijia Wu, Bohan Zhuang, Hong Zhou.
International Conference on Computer Vision Conference (ICCV2023),
Abstract /
arXiv /
BibTex /
Model binarization can significantly compress model size, reduce energy consumption, and accelerate inference through efficient bit-wise operations. Although binarizing convolutional neural networks have been extensively studied, there is little work on exploring binarization on vision Transformers which underpin most recent breakthroughs in visual recognition. To this end, we propose to solve two fundamental challenges to push the horizon of Binary Vision Transformers (BiViT). First, the traditional binary method does not take the long-tailed distribution of softmax attention into consideration, bringing large binarization errors in the attention module. To solve this, we propose Softmax-aware Binarization, which dynamically adapts to the data distribution and reduces the error caused by binarization. Second, to better exploit the information of the pretrained model and restore accuracy, we propose a Cross-layer Binarization scheme and introduce learnable channel-wise scaling factors for weight binarization. The former decouples the binarization of self-attention and MLP to avoid mutual interference while the latter enhances the representation capacity of binarized models. Overall, our method performs favorably against state-of-the-arts by 19.8% on the TinyImageNet dataset. On ImageNet, BiViT achieves a competitive 70.8% Top-1 accuracy over Swin-T model, outperforming the existing SOTA methods by a clear margin.
@InProceedings{he2022bivit,
title={Bivit: Extremely compressed binary vision transformer},
author={He, Yefei and Lou, Zhenyu and Zhang, Luoming and Wu, Weijia and Zhuang, Bohan and Zhou, Hong},
booktitle = {International Conference on Computer Vision Conference 2023},
year = {2023}
}
|
|
|
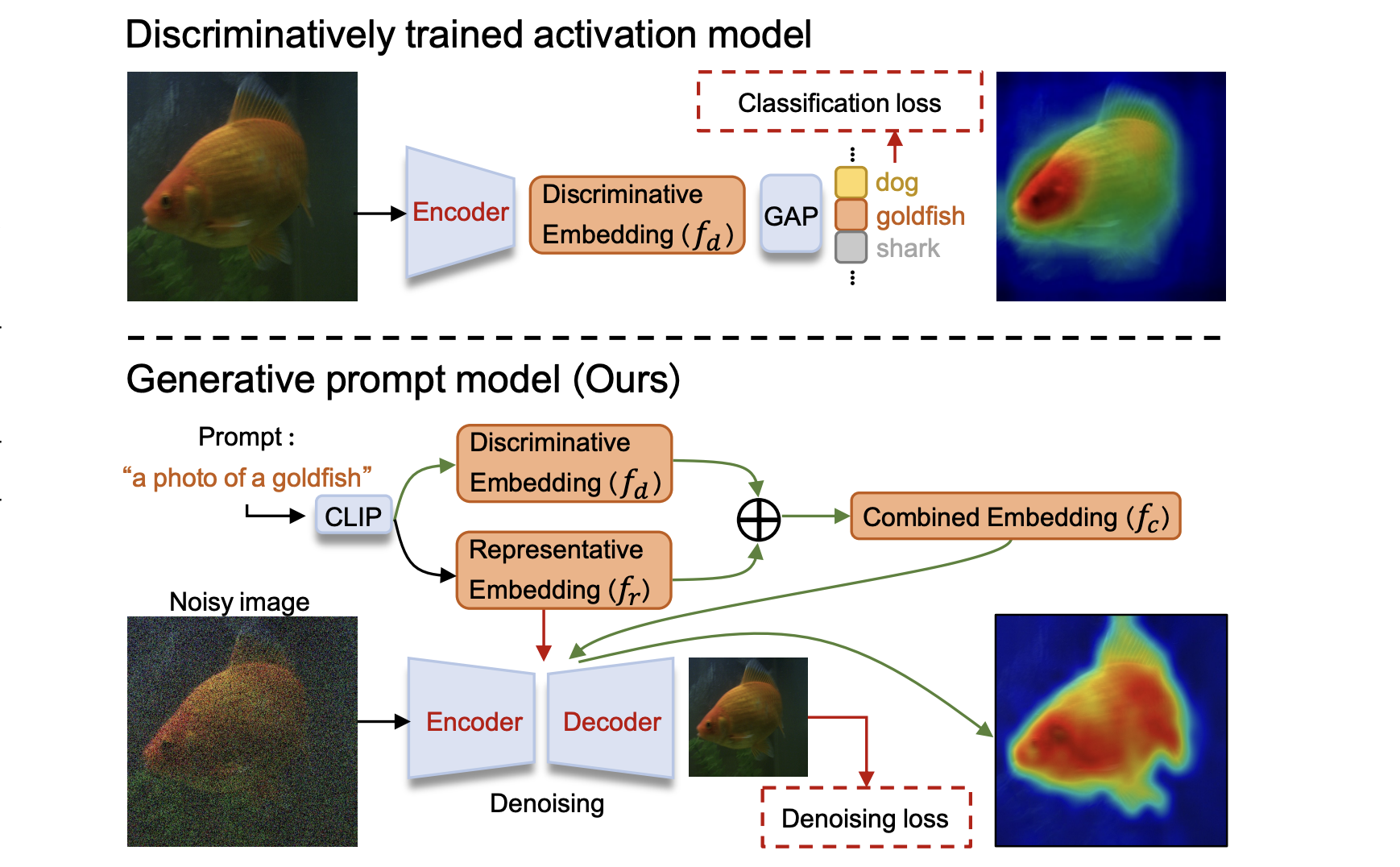
Generative Prompt Model for Weakly Supervised Object Localization
Yuzhong Zhao,Qixiang Ye, Weijia Wu, Chunhua Shen, Fan Wan.
International Conference on Computer Vision Conference (ICCV2023),
Abstract /
arXiv /
BibTex /
GitHub /
Weakly supervised object localization (WSOL) remains challenging when learning object localization models from image category labels. Conventional methods that discriminatively train activation models ignore representative yet less discriminative object parts. In this study, we propose a generative prompt model (GenPromp), defining the first generative pipeline to localize less discriminative object parts by formulating WSOL as a conditional image denoising procedure. During training, GenPromp converts image category labels to learnable prompt embeddings which are fed to a generative model to conditionally recover the input image with noise and learn representative embeddings. During inference, enPromp combines the representative embeddings with discriminative embeddings (queried from an off-the-shelf vision-language model) for both representative and discriminative capacity. The combined embeddings are finally used to generate multi-scale high-quality attention maps, which facilitate localizing full object extent. Experiments on CUB-200-2011 and ILSVRC show that GenPromp respectively outperforms the best discriminative models by 5.2% and 5.6% (Top-1 Loc), setting a solid baseline for WSOL with the generative model.
@InProceedings{zhao2023GPM,
author = {Yuzhong Zhao, Qixiang Ye, Weijia Wu, Chunhua Shen, Fang Wan},
title = {Generative Prompt Model for Weakly Supervised Object Localization},
booktitle = {International Conference on Computer Vision Conference 2023},
year = {2023}
}
|
|
|
DiffuMask: Synthesizing Images with Pixel-level Annotations for Semantic Segmentation Using Diffusion Models
Weijia Wu, Yuzhong Zhao, Mike Zheng Shou, Hong Zhou, Chunhua Shen.
International Conference on Computer Vision Conference (ICCV2023),
Abstract /
arXiv /
BibTex /
GitHub /
Project Page /
Collecting and annotating images with pixel-wise labels is time-consuming and laborious. In contrast, synthetic data can be freely available using a generative model (e.g., DALL-E, Stable Diffusion). In this paper, we show that it is possible to automatically obtain accurate semantic masks of synthetic images generated by the Off-the-shelf Stable Diffusion model, which uses only text-image pairs during training. Our approach, called DiffuMask, exploits the potential of the cross-attention map between text and image, which is natural and seamless to extend the text-driven image synthesis to semantic mask generation. DiffuMask uses text-guided cross-attention information to localize class/word-specific regions, which are combined with practical techniques to create a novel high-resolution and class-discriminative pixel-wise mask. The methods help to reduce data collection and annotation costs obviously. Experiments demonstrate that the existing segmentation methods trained on synthetic data of DiffuMask can achieve a competitive performance over the counterpart of real data (VOC 2012, Cityscapes). For some classes (e.g., bird), DiffuMask presents promising performance, close to the stateof-the-art result of real data (within 3% mIoU gap). Moreover, in the open-vocabulary segmentation (zero-shot) setting, DiffuMask achieves a new SOTA result on Unseen class of VOC 2012.
@InProceedings{wu2023DiffuMask,
author = {Wu, Weijia and Yuzhong, Zhao and Mike Zheng, Shou and Hong Zhou and Shen, Chunhua},
title = {DiffuMask: Synthesizing Images with Pixel-level Annotations for Semantic Segmentation Using Diffusion Models},
booktitle = {arxiv},
year = {2023}
}
|
|
|
End-to-End Video Text Spotting with Transformer
Weijia Wu, Yuanqiang Cai, Chunhua Shen, Debing Zhang, Ying Fu, Ping Luo,
Hong Zhou .
International Journal of Computer Vision (IJCV),
Abstract /
arXiv /
IJCV /
BibTex /
GitHub /
Youtube Demo /
ZhiHu /
Video text spotting(VTS) is the task that requires simultaneously detecting, tracking and recognizing text in video. Recent methods typically follow tracking-by-match paradigm and develop sophisticated pipelines to tackle this task.
In this paper, rooted in Transformer sequence modeling, we propose a simple, but effective end-to-end video text DEtection, Tracking, and Recognition framework (TransDETR). TransDETR mainly includes two advantages: 1) Different from the explicit match paradigm in the adjacent frame,
TransDETR tracks and recognizes each text implicitly by the different query termed `text query' over long-range temporal sequence (more than 7 frames). 2) TransDETR is the first end-to-end trainable video text spotting framework, which simultaneously addresses the three sub-tasks (text detection, tracking, recognition).
Extensive experiments on four video text datasets (ICDAR2013 Video, ICDAR2015 Video, Minetto, and YouTube Video Text) are conducted to demonstrate that \detr achieves the state-of-the-art performance with up to around 7.0% improvements on detection, tracking, and spotting tasks.
@InProceedings{wu2022end,
author = {Weijia Wu, Yuanqiang Cai, Chunhua Shen, Debing Zhang, Ying Fu, Ping Luo, Hong Zhou},
title = {End-to-End Video Text Spotting with Transformer},
booktitle = {International Journal of Computer Vision},
year = {2024}
}
|
|
|
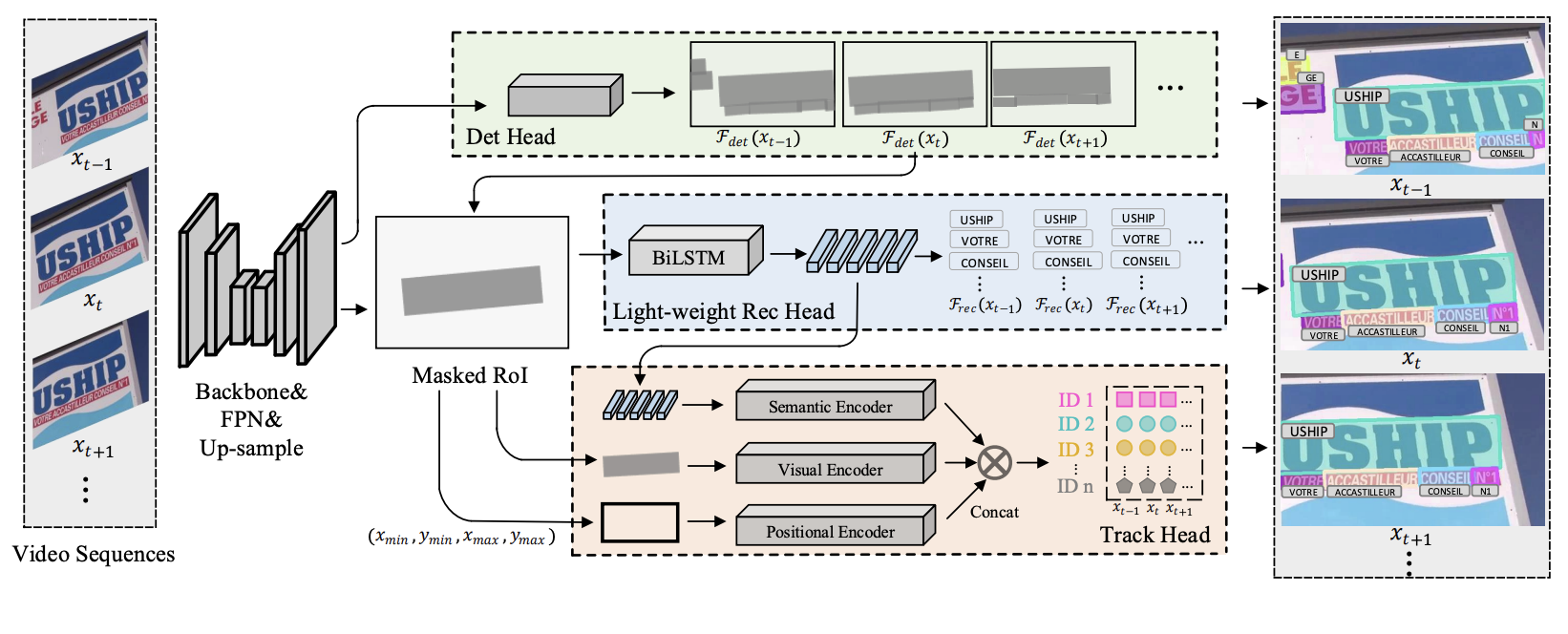
Real-time End-to-End Video Text Spotter with Contrastive Representation Learning
Weijia Wu, Zhuang Li, Jiahong Li, Chunhua Shen, Size Li, Zhongyuan Wang, Ping Luo,
Hong Zhou .
arxiv (arxiv),
Abstract /
arXiv /
BibTex /
Code /
Youtube Demo /
Video text spotting(VTS) is the task that requires simultaneously detecting, tracking and recognizing text instances in the video. Existing video text spotting methods typically develop sophisticated pipelines and multiple models, which is no friend for real-time applications. Here we propose a real-time end-to-end video text spotter with Contrastive Representation learning (CoText). Our contributions are four-fold: 1) For the first time, we simultaneously address the three tasks (e.g., text detection, tracking, recognition) in a real-time end-to-end trainable framework.
2) Like humans, CoText tracks and recognizes texts by comprehending them, relating them each other with visual and semantic representations. 3) With contrastive learning, CoText models long-range dependencies and learning temporal information across multiple frames. 4) A simple, light-weight architecture is designed for effective and accurate performance, including GPU-parallel detection post-processing, CTCbased recognition head with Masked RoI, and track head with contrastive learning. Extensive experiments show the superiority of our method. Especially, CoText achieves an video text spotting IDF1 of 72.0% at 35.2 FPS on ICDAR2015video, with 10.5% and 26.2 FPS improvement
the previous best method.
@InProceedings{wu2022cotext,
author = {Wu, Weijia and Li, Zhuang and Li, Jiahong and Shen, Chunhua and Zhou, Hong and Li, Size and Luo, Ping},
title = {Real-time End-to-End Video Text Spotter with Contrastive Representation Learning},
booktitle = {arxiv},
year = {2022}
}
|
|
|
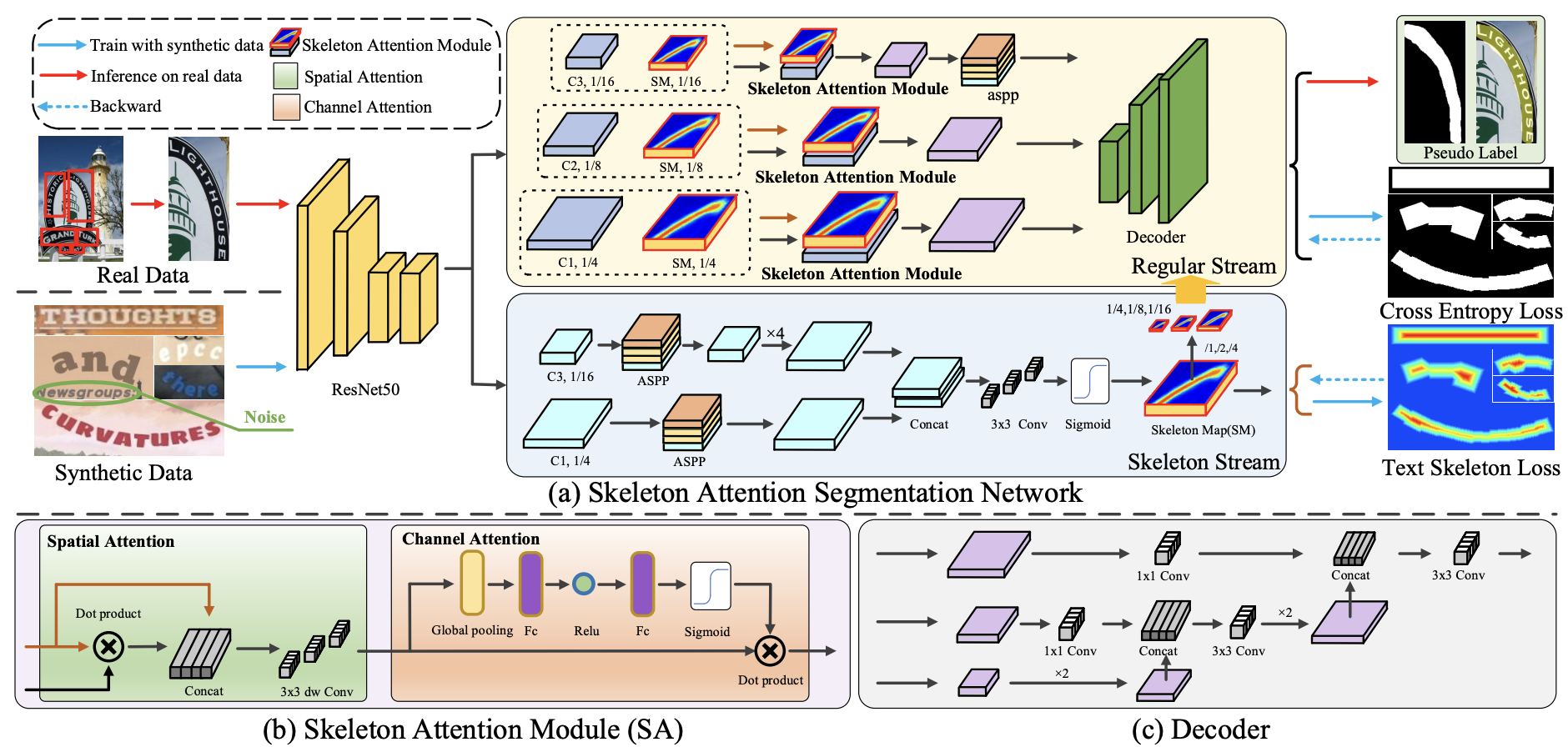
Polygon-free: Unconstrained Scene Text Detection with Box Annotations
Weijia Wu, Enze Xie, Ruimao Zhang, Wenhai Wang, Ping Luo
Hong Zhou .
International Conference on Information Processing (ICIP2022),
Abstract /
arXiv /
BibTex /
Code /
Although a polygon is a more accurate representation than an upright bounding box for text detection, the annotations of polygons are extremely expensive and challenging.
Unlike existing works that employ fully-supervised training with polygon annotations, this study proposes an unconstrained text detection system termed Polygon-free (PF), in which most existing polygon-based text detectors (e.g.,PSENet [33],DB [16]) are trained with only upright bounding box annotations. Our core idea is to transfer knowledge
from synthetic data to real data to enhance the supervision information of upright bounding boxes. This is made possible with a simple segmentation network, namely Skeleton Attention Segmentation Network (SASN), that includes three vital components (i.e., channel attention, spatial attention
and skeleton attention map) and one soft cross-entropy loss. Experiments demonstrate that the proposed Polygonfree system can combine general detectors (e.g., EAST, PSENet, DB) to yield surprisingly high-quality pixel-level results with only upright bounding box annotations on a
variety of datasets (e.g., ICDAR2019-Art, TotalText, ICDAR2015). For example, without using polygon annotations, PSENet achieves an 80.5% F-score on TotalText [3](vs. 80.9% of fully supervised counterpart), 31.1% better than training directly with upright bounding box annotations, and saves 80%+ labeling costs. We hope that
PF can provide a new perspective for text detection to reduce the labeling costs.
@InProceedings{wu2022polygon,
author = {Weijia Wu and Enze Xie and Ruimao Zhang and Wenhai Wang and Ping Luo and Hong Zhou},
title = {Polygon-free: Unconstrained Scene Text Detection with Box Annotations},
booktitle = {IInternational Conference on Information Processing},
year = {2022}
}
|
|
|
A Bilingual, Open World Video Text Dataset and End-to-end Video Text Spotter with Transformer
Weijia Wu, Yuanqiang Cai, Debing Zhang, Jiahong Li
Hong Zhou .
NeurIPS 2021 Track on Datasets and Benchmarks (NeurIPS),
2021
Abstract /
arXiv /
Homepage /
BibTex /
GitHub/
Demo /
中文公众号报道 /
感谢其他人的知乎解读
Most existing video text spotting benchmarks focus on evaluating a single language and scenario with limited data. In this work, we introduce a large-scale, Bilingual, Open World Video text benchmark dataset(BOVText). There are four features for BOVText. Firstly, we provide 2,000+ videos with more than 1,750,000+ frames, 25 times larger than the existing largest dataset with incidental text in videos. Secondly, our dataset covers 30+ open categories with a wide selection of various scenarios, e.g., Life Vlog, Driving, Movie, etc. Thirdly, abundant text types annotation (i.e., title, caption or scene text) are provided for the different representational meanings in video. Fourthly, the BOVText provides bilingual text annotation to promote multiple cultures live and communication. Besides, we propose an end-to-end video text spotting framework with Transformer, termed TransVTSpotter, which solves the multi-orient text spotting in video with a simple, but efficient attention-based query-key mechanism. It applies object features from the previous frame as a tracking query for the current frame and introduces a rotation angle prediction to fit the multiorient text instance. On ICDAR2015(video), TransVTSpotter achieves the state-of-the-art performance with 44.1% MOTA, 9 fps.
@InProceedings{wu2021opentext,
author = {Weijia Wu, Debing Zhang, Yuanqiang Cai, Sibo Wang, Jiahong Li, Zhuang Li, Yejun Tang, Hong Zhou},
title = {A Bilingual, OpenWorld Video Text Dataset and End-to-end Video Text Spotter with Transformer},
booktitle = {35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks},
year = {2021}
}
|
|
|
Synthetic-to-Real Unsupervised Domain Adaptation for Scene Text Detection in the Wild
Weijia Wu, Ning Lu, Enze Xie,
Hong Zhou .
Proceedings of the Asian Conference on Computer Vision (ACCV),
2020.
Abstract /
arXiv /
BibTex
Deep learning-based scene text detection can achieve preferable performance, powered with sufficient labeled training data. However, manual labeling is time consuming and laborious. At the extreme, the corresponding annotated data are unavailable. Exploiting synthetic data is a very promising solution except for domain distribution mismatches between synthetic datasets and real datasets. To address the severe domain distribution mismatch, we propose a synthetic-to-real domain adaptation method for scene text detection, which transfers knowledge from synthetic data (source domain) to real data (target domain). In this paper, a text self-training (TST) method and adversarial text instance alignment (ATA) for domain adaptive scene text detection are introduced. ATA helps the network learn domain-invariant features by training a domain classifier in an adversarial manner. TST diminishes the adverse effects of false positives~(FPs) and false negatives~(FNs) from inaccurate pseudo-labels. Two components have positive effects on improving the performance of scene text detectors when adapting from synthetic-to-real scenes. We evaluate the proposed method by transferring from SynthText, VISD to ICDAR2015, ICDAR2013. The results demonstrate the effectiveness of the proposed method with up to 10% improvement, which has important exploration significance for domain adaptive scene text detection.
@InProceedings{wu2020synthetic,
author = {Wu, Weijia and Lu, Ning and Xie, Enze and Wang, Yuxing and Yu, Wenwen and Yang, Cheng and Zhou, Hong},
title = {Synthetic-to-Real Unsupervised Domain Adaptation for Scene Text Detection in the Wild},
booktitle = {Proceedings of the Asian Conference on Computer Vision (ACCV)},
year = {2020}
}
|
|
Academic Service
Conference Review
International Conference on Machine Learning(ICML), 2022, 2023, 2024, 2025.
Neural Information Processing Systems(NeurIPS), 2021, 2022, 2023, 2024.
Track Datasets and Benchmarks of Neural Information Processing Systems(NeurIPS), 2021, 2022, 2023, 2024, 2025.
The Association for Computational Linguistics (ACL) 2024.
International Conference on Learning Representations(ICLR), 2023, 2024, 2025.
The Association for the Advancement of Artificial Intelligence(AAAI), 2025.
IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 2024, 2025.
European Conference on Computer Vision (ECCV), 2024.
International Conference on Computer Vision (ICCV), 2025.
International Conference and Exhibition on Computer Graphics and Interactive Techniques (SIGGRAPH), 2025.
ACM International Conference on Multimedia (ACM MM), 2025.
CVPR Workshop SyntaGen 2024, 2025.
CVPR 2025 Workshop CVEU.
Journal Review
IEEE Transactions on Neural Networks and Learning Systems (TNNLS).
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT).
IEEE Transactions on Multimedia (TMM).
International Journal of Computer Vision (IJCV).
Transactions on Multimedia Computing Communications and Applications (ACM TOMM).
Engineering Applications of Artificial Intelligence (EAAI).
|
|
Awards
[10/2020] National Scholarship of China.
[03/2025] Excellent Doctoral Dissertation Award of Zhejiang University.
|
|
Talks
[10/2021] MMU, Kuaishou. Video Text Spotting
[08/2025] ICCV 2025 workshops on Generative AI for Storytelling
|

|
|